

Vicky Steeves (@VickySteeves) is the first Research Data Management and Reproducibility Librarian ever! She has held this position at NYU since August 2015 and just published the article Reproducibility Librarianship in “Collaborative Librarianship” describing her role. We interviewed her to learn what it takes to be a reproducibility librarian and why creating this new job title is key for the scientific community.
Vicky defines reproducibility as “when someone independently confirms results with the same data and code or tools.” She works particularly on computational  reproducibility, ensuring these tools/code work across computational environments, and firmly believes that librarians ought to work hand-in-hand with researchers to successfully make science more reproducible.
reproducibility, ensuring these tools/code work across computational environments, and firmly believes that librarians ought to work hand-in-hand with researchers to successfully make science more reproducible.
JoVE: Did you publish the article in “Collaborative Librarianship” in response to the community’s reaction to your title?
Vicky Steeves: Researchers are surprised the library would support reproducibility, other librarians are surprised as no one else has this title in libraryland! I wrote ‘Reproducibility Librarianship’ to shed light on my role. I had frequent questions from colleagues in leadership positions at their institutions, who asked about my role and approach, and successes and failures. I hope the piece will encourage institutions that support research (museums, academia, industry, etc.) to have reproducibility librarians of their own, and serve as evidence to those colleagues who reached out, to help them persuade their Deans to give them the money to hire and support someone in this position.
J: Why should people prioritize reproducibility in their work?
VS: I would place reproducibility and openness of research on the top of the list of priorities for researchers, librarians included. In my view, reproducibility is nothing without openness. If someone claims their work is reproducible, then they should invite others to reproduce it, transparently, by making the data, analysis tools (like code), and documentation available. It’s ethical and promotes excellence in research.
J: Do librarians have a responsibility in making research reproducible?
VS: Librarians and archivists have a central role to play in reproducibility because 1) we’re researchers and have a stake in our own work, and 2) it’s our job to preserve and make available (and reusable) materials of all kinds.
We are curators, and research output is no different. We keep thousands of field journals, research papers, and dissertations and make them available. Keeping the materials that support and verify claims in those texts is a logical next step, and as librarians and archivists, we also need the tools to make those available to others. R code needs R, Matlab code needs Matlab. To me, it’s part and parcel of our role in assisting other researchers, in archiving the scholarly record, and in engaging in good scholarship for our own selves.
J: What facet of reproducibility are you specializing in?
VS: Reproducibility is made so much more challenging because of computers, and the dominance of closed-source operating systems and analysis software researchers use. Ben Marwick wrote a great piece called ‘How computers broke science – and what we can do to fix it’ which details a bit of the problem. Basically, computational environments affect the outcome of analyses (Gronenschild et. al (2012) showed the same data and analyses gave different results between two versions of macOS), and are exceptionally hard to reproduce, especially when the license terms don’t allow it. Additionally, programs encode data incorrectly and studies make erroneous conclusions, e.g. Microsoft Excel encodes genes as dates, which affects 1/5 of published data in leading genome journals. These same problems affect open source operating systems and tools as well, to a lesser degree.
Most dependencies of research done on a computer are unknown to the user, and deeply affect the reproducibility of their work. It’s called ‘dependency hell,’ because it’s a rabbit hole of X depends on Z depends on A, etc. Basically, reproducibility needs:
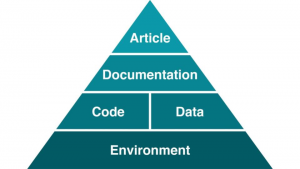
So, technology to capture computational environments, workflow, provenance, data, and code are hugely impactful for reproducibility. It’s been the focus of my work, in supporting an open source tool called ReproZip, which packages all computational dependencies, data, and applications in a single distributable package that other can reproduce across different systems. There are other tools that fix parts of this problem: Kepler and VisTrails for workflow/provenance, Packrat for saving specific R packages at the time a script is run so updates to dependencies won’t break, Pex for generating executable Python environments, and o2r for executable papers (including data, text, and code in one).
J: What successes can you highlight from these past two years on the job?
VS: I work a lot on computational reproducibility and I’d like to think we’ve made quite a lot of advancements since I joined NYU and consequently, the ReproZip team. I believe very much that ReproZip can solve a lot of problems in computational reproducibility, and so I work hard to show the tool to a wide variety of researchers (some have let us publicize their work). There’s been an uptick in users, we’ve developed a lot of useful new features (including a plugin for Jupyter notebooks), and added a user interface to make it friendlier to folks not comfortable on the command line.
Data management and reproducibility are also gaining traction at NYU now that we have a service to assist patrons. Requests for embedded classes, workshops, and consultations have been steadily rising since I arrived at NYU two years ago, and Nicholas Wolf (Research Data Management Librarian) and I started building the service together. The first year was a lot of outreach, and we’re reaping the benefits of that this year.
J: Faculty and researcher consultations are a large part of your job. Why are they important?
VS: Every consultation varies. Students, staff, or faculty members request a meeting to discuss their problems in data management and reproducibility. They let me know in advance the problem or question they have, I do my best to prepare for it, and then we meet to discuss options, best practices, and tools. Sometimes it’s helping them migrate file

formats from something which can’t be opened anymore (e.g. they can’t pay for the software anymore), sometimes it’s helping them plan an organizational strategy for new projects, sometimes it’s an introduction to ReproZip, and sometimes it’s helping them prep data, documentation, and code for submission into a repository.
I do this in collaboration with Nick Wolf, a data management librarian at NYU. The two of us work together on consultations, classes, and workshops within NYU. I also hold office hours on my own at the Center for Data Science for folks to drop in with questions on reproducibility, data management, etc.
More generally, I see a lot more people focusing on computational reproducibility, which is great. I also love seeing more folks connect data management to reproducibility. I see good data management as a necessary component of reproducibility and teach it that way in my workshops for the NYU community.
J: Where to start if you want to become a reproducibility librarian?
VS: There are so many articles now about reproducibility. There are a few good ones for folks just starting out:
- ‘The Recomputation Manifesto’
- 4 Scientists Leading the Charge to Solve the Reproducibility Crisis
- ‘Five selfish reasons to work reproducibly’
- ‘How computers broke science – and what we can do to fix it
- ‘Ten Simple Rules for the Care and Feeding of Scientific Data’
- The Practice of Reproducible Research
I would also recommend going to conferences:
- FORCE11 is a great conference for open access/source, data management, and reproducibility.
- Research Data Access and Preservation (RDAP) is another great conference with more of a librarian focus.
- Library and Information Technology Association (LITA) Forum is another librarian-focused meeting that usually has data management and reproducibility sessions.
There are a lot of one-offs as well – folks having a one or two-day symposium on reproducibility (I am guilty of this myself). Keep on top of events with Twitter!
Ed. Note: This interview has been lightly edited for clarity and length.
