

Summary
I modelli ad effetti misti sono strumenti flessibili e utili per analizzare i dati con una struttura stocastica gerarchica nella silvicoltura e potrebbero anche essere utilizzati per migliorare significativamente le prestazioni dei modelli di crescita forestale. Qui viene presentato un protocollo che sintetizza le informazioni relative ai modelli lineari ad effetti misti.
Abstract
Qui, abbiamo sviluppato un modello a albero individuale di incrementi di area basale di 5 anni basati su un set di dati che include 21898 alberi picea asperata da 779 appezzamenti campione situati nella provincia dello Xinjiang, nel nord-ovest della Cina. Per evitare alte correlazioni tra le osservazioni della stessa unità di campionamento, abbiamo sviluppato il modello utilizzando un approccio lineare ad effetti misti con effetto grafico casuale per tenere conto della variabilità stocastica. Varie variabili ad albero e stand-level, come gli indici per le dimensioni degli alberi, la concorrenza e le condizioni del sito, sono state incluse come effetti fissi per spiegare la variabilità residua. Inoltre, l'eteroscedasticità e l'autocorrelazione sono state descritte introducendo funzioni di varianza e strutture di autocorrelazione. Il modello ottimale degli effetti misti lineari è stato determinato da diverse statistiche di adattamento: il criterio informativo di Akaike, il criterio dell'informazione bayesiana, la probabilità logaritmo e un test del rapporto di verosimiglianza. I risultati hanno indicato che variabili significative dell'incremento dell'area basale del singolo albero erano la trasformazione inversa del diametro all'altezza del seno, l'area basale degli alberi più grande dell'albero soggetto, il numero di alberi per ettaro e l'elevazione. Inoltre, gli errori nella struttura di varianza sono stati modellati con maggior successo dalla funzione esponenziale, e l'autocorrelazione è stata significativamente corretta dalla struttura autoregressiva di primo ordine (AR(1)). Le prestazioni del modello lineare degli effetti misti sono state significativamente migliorate rispetto al modello utilizzando la regressione ordinaria dei meno quadrati.
Introduction
Rispetto alla monocoltura invecchiata uniforme, la gestione forestale di specie miste di età irregolare con molteplici obiettivi ha ricevuto recentementeuna maggiore attenzione 1,2,3. La previsione di diverse alternative di gestione è necessaria per formulare solide strategie di gestione forestale, in particolare per la complessa foresta di specie miste di età irregolare4. I modelli di crescita e resa delle foreste sono stati ampiamente utilizzati per prevedere lo sviluppo e il raccolto di alberi o standnell'ambito di vari schemi di gestione 5,6,7. I modelli di crescita e resa delle foreste sono classificati in modelli a albero singolo, modelli di classe di dimensioni e modelli di crescita interi6,7,8. Sfortunatamente, i modelli di classe di dimensioni e i modelli di stand interi non sono appropriati per le foreste di specie miste di età non uniforme, che richiedono una descrizione più dettagliata per sostenere il processo decisionale di gestione forestale. Per questo motivo, i modelli di crescita e resa dei singoli alberi hanno ricevuto una maggiore attenzione negli ultimi decenni a causa della loro capacità di fare previsioni per gli stand forestali con una varietà di composizioni, strutture e strategie digestione delle specie 9,10,11.
La regressione OLS (Ordinary Least Squares) è il metodo più comunemente utilizzato per lo sviluppo di modelli di crescita di singoli alberi12,13,14,15. I set di dati per i singoli modelli di crescita degli alberi raccolti ripetutamente per un periodo di tempo fisso sulla stessa unità di campionamento (ad esempio, grafico campione o albero) hanno una struttura stocastica gerarchica, con una mancanza di indipendenza e un'elevata correlazione spaziale e temporale tra leosservazioni 10,16. La struttura stocastica gerarchica viola le ipotesi fondamentali della regressione OLS: vale a dire residui indipendenti e dati normalmente distribuiti con varianze uguali. Pertanto, l'utilizzo della regressione OLS produce inevitabilmente stime distorte dell'errore standard delle stime dei parametriper questi dati 13,14.
I modelli ad effetti misti forniscono un potente strumento per analizzare i dati con strutture complesse, ad esempio dati di misure ripetute, dati longitudinali e dati a più livelli. I modelli ad effetti misti sono costituiti sia da componenti fissi, comuni alla popolazione completa, sia da componenti casuali, specifici di ogni livello di campionamento. Inoltre, i modelli ad effetti misti tengono conto dell'eterogeneità e dell'autocorrelazione nello spazio e nel tempo definendo matrici di struttura varianza-covarianza non diagonali17,18,19. Per questo motivo, i modelli ad effetto misto sono stati ampiamente utilizzati nella silvicoltura, come nei modelli di diametro-altezza20,21,modelli acorona 22,23,modelli auto-assottiglianti24,25e modelli dicrescita 26,27.
Qui, l'obiettivo principale era quello di sviluppare un modello di incremento dell'area basale a singolo albero utilizzando un approccio lineare ad effetti misti. Speriamo che l'approccio basato sugli effetti misti possa essere ampiamente applicato.
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. Preparazione dei dati
- Preparare i dati di modellazione, che includono informazioni sui singoli alberi (specie e diametro all'altezza del seno a 1,3 m) e informazioni sulla trama (pendenza, aspetto e elevazione). In questo studio, i dati sono stati ottenuti dall'8 ° (2009) e dal 9 ° (2014) inventario forestale nazionale cinese nella provincia dello Xinjiang, nel nord-ovest della Cina, che include 21.898 osservazioni di 779 appezzamenti campione. Questi appezzamenti campione sono a forma quadrata con una dimensione di 1 Mu (unità di area cinese equivalente a 0,067 ha) e sono sistematicamente disposti su una griglia di 4 km x 8 km.
NOTA: I dati per la modellazione (area basale) richiedono almeno un periodo di crescita (cioè due osservazioni). - Dividi casualmente i dati in due set di dati, con l'80% dei dati dei grafici campione utilizzati per il raccordo del modello (set di dati di sviluppo del modello), che consiste in 17.145 osservazioni da 623 grafici campione e il 20% per la convalida del modello (set di dati di convalida del modello) che consiste in 4.753 osservazioni da 156 grafici campione. Le statistiche descrittive delle variabili chiave utilizzate sono fornite nella tabella 1.
NOTA: questo passaggio della procedura di modellazione può essere omesso e tutti i dati vengono utilizzati per lo sviluppo del modello.
| Variabili | Dati di montaggio | Dati di convalida | |||||||
| Minimo | Massimo | Significare | S.d. | Minimo | Massimo | Significare | S.d. | ||
| DBH1 (cm) | 5 | 124.8 | 19.9 | 13.2 | 5 | 101.5 | 19.5 | 13.4 | |
| QMD (cm) | 6.7 | 82.3 | 22.5 | 8.5 | 9.2 | 73.3 | 21.8 | 9.2 | |
| ID (cm) | 0.1 | 14.4 | 1.1 | 1 | 0.1 | 16.9 | 1 | 1.1 | |
| BAL (m3) | 0 | 5.2 | 1.7 | 0.9 | 0 | 5.4 | 1.7 | 1 | |
| NT (alberi/ha) | 14.9 | 3642 | 1072 | 673.7 | 14.9 | 3418 | 1205 | 829.3 | |
| BA (m2/ha) | 0.1 | 77.5 | 34.2 | 13.9 | 0.1 | 80.6 | 34.5 | 15.3 | |
| El (m) | 2 | 3302 | 2189 | 340.3 | 1441 | 3380 | 2256 | 308.3 | |
La tabella 1. Statistiche di riepilogo per l'adattamento e la convalida dei dati. DBH1: diametro iniziale all'altezza del seno a 1,3 m (DBH), DBH2: DBH misurato dopo 5 anni di crescita, QMD: diametro medio quadratico, ID: incremento del diametro per 5 anni (DBH2 – DBH1), BAL: l'area basale degli alberi più grande dell'albero soggetto (l'albero soggetto: l'albero che è stato calcolato gli indici di competizione), NT: il numero di alberi per ettaro, BA: area basale per ettaro, EL: elevazione, S.D.: deviazione standard.
2. Sviluppo di modelli di base
- Consultare i riferimenti per identificare le variabili che influiscono sugli incrementi dell'area basale dei singoli alberi.
- Selezionare e calcolare le variabili in base ai dati. In genere, l'incremento dell'area basale del singolo albero è influenzato da tre gruppi di variabili: dimensione dell'albero, competizione e condizionedel sito 27,28,29,30.
- Si consideri gli effetti delle dimensioni degli alberi quali DBH1, il quadrato di DBH1 (
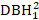 ), latrasformazione inversa di DBH 1 (1/DBH1) e il logaritmo comune di DBH1 (logDBH1) o le loro combinazioni.
), latrasformazione inversa di DBH 1 (1/DBH1) e il logaritmo comune di DBH1 (logDBH1) o le loro combinazioni. - Si consideri gli effetti competitivi, come gli indici di concorrenza a una o due lati, per quantificare in modo più completo il livello di concorrenza vissuto da un albero, nonché la sua posizione sociale all'interno dello stand. La competizione unilaterale include BAL e l'indice di densità relativa (RD=DBH1/QMD); la competizione su due lati include NT e BA.
NOTA: gli indici di concorrenza dipendenti dalla distanza dovrebbero essere presi in considerazione se i dati sono disponibili. - Considerare che gli effetti del sito, ad esempio aspect (ASP), slope (SL) e EL. SL e ASP, devono essere inclusi utilizzando latrasformazione 31 diStage.
- Si consideri gli effetti delle dimensioni degli alberi quali DBH1, il quadrato di DBH1 (
- Selezionare log(
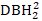 - +1) ( indica il quadrato di DBH2) come variabile dipendente.
- +1) ( indica il quadrato di DBH2) come variabile dipendente. - Sviluppare il modello di base utilizzando il metodo di regressione graduale. Assicurarsi che il modello sia biologicamente ragionevole e mostri differenze significative tra variabili indipendenti. Utilizzare il fattore di inflazione di varianza (VIF) per verificare la multicollinearità.
- Lasciare le variabili indipendenti con p < 0.05 e VIF < 5 nel modello di base.
- Produrre i risultati del modello di base e il plottaggio residuo. Il modello di base qui prodotto funge da base per l'ulteriore sviluppo di un modello ad effetti misti.
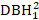 ), latrasformazione inversa di DBH 1 (1/DBH1) e il logaritmo comune di DBH1 (logDBH1) o le loro combinazioni.
), latrasformazione inversa di DBH 1 (1/DBH1) e il logaritmo comune di DBH1 (logDBH1) o le loro combinazioni.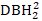 -
- 3. Sviluppo lineare di modelli ad effetti misti con il pacchetto "nlme" nel software R
- Leggere il set di dati di sviluppo del modello e caricare il pacchetto "nlme".
>model.development.dataset=read.csv("E:/DATA/JoVE/modelingdata.csv",
header=TRUE)
>libreria(nlme) - Selezionate i grafici campione come effetti casuali per sviluppare il modello degli effetti misti.
- Adatta tutte le possibili combinazioni di effetti casuali con il metodo di massima verosimiglianza (ML) e restituisci i risultati.
>Modello<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset,
method="ML", casuale =~1| TRAMA)
>riepilogo(Modello)- Set random =~1 è l'intercetta su parametri casuali. Modificare le istruzioni casuali fino a quando non vengono montate tutte le combinazioni. Ad esempio, per impostare 1/DBH1 e BAL come parametri casuali, il codice è il seguente: casuale =~1/DBH1+BAL-1. Inoltre, nel processo di montaggio, i codici possono segnalare errori dovuti alla non converenza del modello montato.
- Selezionare il modello migliore in base al criterio informativo (AIC) di Akaike, al criterio dell'informazione bayesiana (BIC), alla probabilità logaritmo (Loglik) e al test del rapporto di verosimiglianza (LRT).
>anova(Modello.1, Modello.6)
>anova(Modello.6, Modello.23)
>anova(Modello.23, Modello.30) - Determinare la struttura di Ri. Affrontare l'eterogeneità e l'autocorrelazione di Ri32. La Ri è scritta come segue:
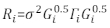 (1)
(1)
dove σ2 è un fattore di scala sconosciuto che è uguale alla varianza residua del modello, G iè una matrice diagonale che descrive l'eterogeneità, e Γ i èuna matrice che descrive l'autocorrelazione.- Osservare se i residui hanno eteroscedasticità dalla trama residua. Se c'è eteroscedasticità (i residui hanno un modello o una tendenza chiara), introdurre tre funzioni di varianza usate di frequente - la costante più la funzione di potenza, la funzione di potenza e la funzione esponenziale - per modellare la struttura di varianza degli errori.
> La commissione per l'Model.30.1<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",random=~1/DBH1+BAL+NT| Trama
weights=varConstPower(form=~ montato(.)))
> La commissione per l'riepilogo(Modello.30.1)
> La commissione per l'Model.30.2<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",random=~1/DBH1+BAL+NT| Trama
weights=varPower(form=~ montato(.)))
> La commissione per l'riepilogo(Modello.30.2)
> La commissione per l'Model.30.3<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",random=~1/DBH1+BAL+NT| Trama
weights=varExp(form=~ montato(.)))
>riepilogo(Modello.30.3) - Determinare la migliore funzione di varianza per il modello in base a AIC, BIC, Loglik e LRT.
> La commissione per l'anova(Modello.30, Modello.30.1)
> La commissione per l'anova(Modello.30, Modello.30.2)
>anova(Modello.30, Modello.30.3) - Introdurre tre strutture di autocorrelazione comunemente utilizzate - la struttura di simmetria composta (CS), la struttura autoregressiva del primo ordine [AR(1)] e una combinazione di strutture autoregressive e medie mobili di primo ordine [ARMA(1,1)], per tenere conto dell'autocorrelazione.
>Modello.30.3.1<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",
random=~1/DBH1+BAL+NT| PLOT, weights=varExp(form=~fitted(.)), corr= corCompSymm())
>riepilogo(Modello.30.3.1)
>Modello.30.3.2<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",
random=~1/DBH1+BAL+NT| PLOT,weights=varExp(form=~ fitted(.)), corr=corAR1())
>riepilogo(Modello.30.3.2)
>Modello.30.3.3<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",
random=~1/DBH1+BAL+NT| PLOT,weights=varExp(form=~ fitted(.)), corr=corARMA(q=1,p=1))
>riepilogo(Modello.30.3.3) - Determinare la migliore struttura di autocorrelazione in base a AIC, BIC, Loglik e LRT.
>anova(Modello.30.3, Modello.30.3.2)
NOTA: I Gi e Γi non possono essere definiti se non vi è eteroscedasticità e autocorrelazione. - Produrre i risultati finali del modello ad effetti misti utilizzando il metodo REML (Restricted Maximum Likelihood).
>Mixed.model<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="REML",random=~1/DBH1+BAL+NT| Trama
weights=varExp(form=~ fitted(.)), corr=corAR1())
>riepilogo(Misto.modello)
- Osservare se i residui hanno eteroscedasticità dalla trama residua. Se c'è eteroscedasticità (i residui hanno un modello o una tendenza chiara), introdurre tre funzioni di varianza usate di frequente - la costante più la funzione di potenza, la funzione di potenza e la funzione esponenziale - per modellare la struttura di varianza degli errori.
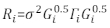 (1)
(1)4. Correzione dei pregiudizi
- Trasformate i valori previsti dell'incremento dell'area basale utilizzando il modello finale su una scala logaritmica nella scala originale. Tuttavia, una tale trasformazione posteriore lineare del valore previsto da un modello trasformato da log produce una distorsione di trasformazione del log associata. Per gestire la distorsione del log, è stato derivato e integrato un fattore di correzione nell'equazione di previsione, che stima l'incremento effettivo previsto dell'area basale per un dato albero [Equazione (2)]:
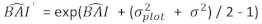 (2)
(2)
dove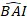 è previsto il valore logaritmico dell'incremento dell'area basale dal modello,
è previsto il valore logaritmico dell'incremento dell'area basale dal modello, 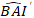 mentre è il valore di trasformazione posteriore previsto dell'incremento dell'area basale per 5 anni dopo la correzione per la distorsione della trasformazione del log.
mentre è il valore di trasformazione posteriore previsto dell'incremento dell'area basale per 5 anni dopo la correzione per la distorsione della trasformazione del log. 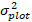 è la varianza dagli effetti casuali nel grafico e σ2 è la varianza residua.
è la varianza dagli effetti casuali nel grafico e σ2 è la varianza residua. - Convertire l'incremento dell'area basale ( ) nell'incremento del diametro.
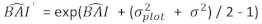 (2)
(2)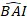 è previsto il valore logaritmico dell'incremento dell'area basale dal modello,
è previsto il valore logaritmico dell'incremento dell'area basale dal modello, 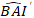 mentre è il valore di trasformazione posteriore previsto dell'incremento dell'area basale per 5 anni dopo la correzione per la distorsione della trasformazione del log.
mentre è il valore di trasformazione posteriore previsto dell'incremento dell'area basale per 5 anni dopo la correzione per la distorsione della trasformazione del log. 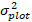 è la varianza dagli effetti casuali nel grafico e σ2 è la varianza residua.
è la varianza dagli effetti casuali nel grafico e σ2 è la varianza residua.5. Previsione e valutazione del modello
- Preparare il set di dati di convalida del modello prodotto nella sezione 1.2 per la stima.
- Utilizzate il modello lineare degli effetti misti per prevedere l'incremento dell'area basale a singolo albero. I componenti casuali sono stati calcolati utilizzando il seguente miglior predittore lineare imparziale:
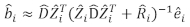 (3)
(3)
dove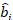 è un vettore per i componenti casuali; è la matrice varianza-covarianza per la variabilità tra grafici; è la matrice di progettazione per i componenti casuali che agiscono alle osservazioni complementari; è il vettore residuo le cui componenti sono date dalla differenza tra gli
è un vettore per i componenti casuali; è la matrice varianza-covarianza per la variabilità tra grafici; è la matrice di progettazione per i componenti casuali che agiscono alle osservazioni complementari; è il vettore residuo le cui componenti sono date dalla differenza tra gli 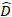
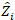
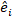 incrementi dell'area basale e gli incrementi previsti utilizzando il modello ad effetti fissi.
incrementi dell'area basale e gli incrementi previsti utilizzando il modello ad effetti fissi. - Valutare e confrontare la capacità predittiva del modello di base e del modello lineare degli effetti misti utilizzando i seguentitre indicatori statistici 23,33.
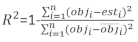 (4)
(4)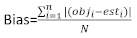 (5)
(5)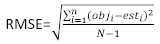 (6)
(6)
dove obji è l'area basale incrementa, est i è l'area basale prevista incrementi,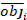 è la media delle osservazioni, e N è il numero di osservazioni.
è la media delle osservazioni, e N è il numero di osservazioni.
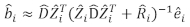 (3)
(3)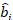 è un vettore per i componenti casuali; è la matrice varianza-covarianza per la variabilità tra grafici; è la matrice di progettazione per i componenti casuali che agiscono alle osservazioni complementari; è il vettore residuo le cui componenti sono date dalla differenza tra gli
è un vettore per i componenti casuali; è la matrice varianza-covarianza per la variabilità tra grafici; è la matrice di progettazione per i componenti casuali che agiscono alle osservazioni complementari; è il vettore residuo le cui componenti sono date dalla differenza tra gli 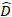
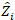
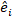 incrementi dell'area basale e gli incrementi previsti utilizzando il modello ad effetti fissi.
incrementi dell'area basale e gli incrementi previsti utilizzando il modello ad effetti fissi.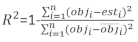 (4)
(4)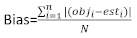 (5)
(5)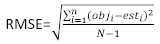 (6)
(6)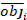 è la media delle osservazioni, e N è il numero di osservazioni.
è la media delle osservazioni, e N è il numero di osservazioni.Subscription Required. Please recommend JoVE to your librarian.
Representative Results
Il modello base di incremento dell'area basale per P. asperata è stato espresso come Equazione (7). Le stime dei parametri, i relativi errori standard e le statistiche sulla mancanza di adattamento sono riportati nella tabella 2. Il grafico residuo è illustrato nella figura 1. È stata osservata una pronunciata eterogeneità dei residui. (7)
(7)
| Stima | Errore standard | test t | Valore P | Vif | |
| Int | 2.41 | 2.26E-02 | 106.78 | <2e-16 | - |
| 1/DBH1 | -5.84 | 7.57E-02 | -77.19 | <2e-16 | 1.12 |
| Bal | -0.0954 | 3.34E-03 | -28.54 | <2e-16 | 1.08 |
| Nt | -0.000158 | 4.74E-06 | -33.31 | <2e-16 | 1.12 |
| El | -0.00011 | 9.07E-06 | -12.13 | <2e-16 | 1.05 |
| AIC = 16789 | |||||
| BIC = 16836 | |||||
| Loglik = -8389 | |||||
La tabella 2. Risultati del modello di base. I parametri stimati, i relativi errori standard e le statistiche di insaderenti derivate dall'equazione (7). VIF: fattore di inflazione di varianza, AIC: Criterio informativo di Akaike, BIC: criterio di informazione bayesiana, e Loglik: verosimiglianza logaritmo.

Figura 1. Grafico residuo derivato dall'equazione (7). I residui hanno una chiara tendenza, vale a dire che è stata osservata una pronunciata eteroscedasticità dei residui. Clicca qui per visualizzare una versione più grande di questa figura.
C'erano 31 possibili combinazioni di parametri di effetti casuali per l'equazione (7). Dopo il montaggio, 30 combinazioni hanno raggiunto la convergenza(tabella 3). Tra queste 30 combinazioni, il Modello 30 dell'Equazione (8) è stato selezionato poiché ha prodotto l'AIC più basso (9083), il BIC più basso (9207), il più grande LogLik (-4525) e l'LRT era significativamente diverso rispetto agli altri modelli. (8)
(8)
dove β1 – β5 sono i parametri degli effetti fissi e b1 – b4 sono i parametri degli effetti casuali.
| Modello | Parametri casuali | Aic | Bic | LogLik | Lrt | Valore P | ||||
| Int | 1/DBH1 | Bal | Nt | El | ||||||
| 1 | ▲ | 10175 | 10230 | -5081 | ||||||
| 2 | ▲ | 11630 | 11684 | -5808 | ||||||
| 3 | ▲ | 11772 | 11826 | -5879 | ||||||
| 4 | ▲ | 10556 | 10611 | -5271 | ||||||
| 5 | ▲ | 10259 | 10313 | -5123 | ||||||
| 6 | ▲ | ▲ | 9268 | 9338 | -4625 | 911.1 | <.0001 | |||
| (1 contro 6) | ||||||||||
| 7 | ▲ | ▲ | 9411 | 9481 | -4697 | |||||
| 8 | ▲ | ▲ | 10179 | 10249 | -5081 | |||||
| 9 | ▲ | ▲ | 10179 | 10249 | -5080 | |||||
| 10 | ▲ | ▲ | 10829 | 10899 | -5406 | |||||
| 11 | ▲ | ▲ | 9532 | 9601 | -4757 | |||||
| 12 | ▲ | ▲ | 9335 | 9405 | -4659 | |||||
| 13 | ▲ | ▲ | 9803 | 9873 | -4892 | |||||
| 14 | ▲ | ▲ | 9465 | 9535 | -4723 | |||||
| 15 | ▲ | ▲ | 10200 | 10270 | -5091 | |||||
| 16 | ▲ | ▲ | ▲ | Non converenza | ||||||
| 17 | ▲ | ▲ | ▲ | 9271 | 9364 | -4624 | ||||
| 18 | ▲ | ▲ | ▲ | 9274 | 9367 | -4625 | ||||
| 19 | ▲ | ▲ | ▲ | 9417 | 9510 | -4696 | ||||
| 20 | ▲ | ▲ | ▲ | 9417 | 9510 | -4697 | ||||
| 21 | ▲ | ▲ | ▲ | 10184 | 10277 | -5080 | ||||
| 22 | ▲ | ▲ | ▲ | 9332 | 9425 | -4654 | ||||
| 23 | ▲ | ▲ | ▲ | 9132 | 9225 | -4554 | 142.7 | <.0001 | ||
| (23 vs 6) | ||||||||||
| 24 | ▲ | ▲ | ▲ | 9293 | 9386 | -4634 | ||||
| 25 | ▲ | ▲ | ▲ | 9443 | 9536 | -4709 | ||||
| 26 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | |||
| 27 | ▲ | ▲ | ▲ | ▲ | 9086 | 9210 | -4527 | |||
| 28 | ▲ | ▲ | ▲ | ▲ | 9280 | 9404 | -4624 | |||
| 29 | ▲ | ▲ | ▲ | ▲ | 9425 | 9549 | -4696 | |||
| 30 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | 56.8 | <.0001 | |
| (30 vs 23) | ||||||||||
| 31 | ▲ | ▲ | ▲ | ▲ | ▲ | 9091 | 9254 | -4525 | ||
La tabella 3. Indici di valutazione di ciascun modello lineare ad effetti misti. -: è stato selezionato un parametro per gli effetti casuali per il montaggio; LRT: test del rapporto di verosimiglianza.
I modelli lineari ad effetti misti con funzioni di varianza e strutture di correlazione sono riportati nella tabella 4. Secondo AIC, BIC, Loglik e LRT, la funzione esponenziale e AR(1) sono state selezionate rispettivamente come migliore funzione di varianza e struttura di autocorrelazione.
| Modello | Varianza (funzione) | Struttura di correlazione | Aic | Bic | LogLik | Lrt | Valore P |
| 30 | No | Indipendente | 9083 | 9207 | -4525 | ||
| 30.1 | ConstPower | Indipendente | 9075 | 9215 | -4520 | 11.8a | 0.0028 |
| 30.2 | Potere | Indipendente | 9073 | 9205 | -4520 | 11.7a | 6.00E-04 |
| 30.3 | Esponente | Indipendente | 9073 | 9204 | -4519 | 12.3a | 5.00E-04 |
| 30.3.1 | Esponente | Cs | Non converenza | ||||
| 30.3.2 | Esponente | AR(1) | 9050 | 9189 | -4507 | 24.9b) la commissione per i trasporti e il | <.0001 |
| 30.3.3 | Esponente | ARMA(1,1) | Non converenza | ||||
La tabella 4. Confronti delle prestazioni dei modelli lineari di incremento dell'area basale ad albero singolo ad effetti misti con diverse funzioni di varianza e diverse strutture di correlazione. CS: struttura di simmetria composta, AR(1): una struttura autoregressiva di primo ordine, ARMA(1,1): una combinazione di strutture autoregressive e medie mobili di primo ordine; è stato calcolato un rapporto di verosimiglianza per il Modello 30; b Il rapporto di verosimiglianza è stato calcolato per il modello 30.3.
Il modello finale di incremento lineare dell'area basale ad albero singolo ad effetti misti è stato proposto utilizzando il metodo REML [Equazione (9)]. I parametri fissi stimati, i relativi errori standard e le statistiche sulla mancanza di adattamento sono riportati nella tabella 5. Il grafico residuo del modello finale è illustrato nella figura 2. Nei residui si è osservato un miglioramento significativo. (9)
(9)
Dove (10)
(10)
| Stima | Errore standard | test t | Valore P | |
| Int | 2.8086 | 7.99E-02 | 35.14 | <0,01 |
| 1/DBH1 | -6.2402 | 1.56E-01 | -40.01 | <0,01 |
| Bal | -0.1324 | 8.07E-03 | -16.41 | <0,01 |
| Nt | -0.0001 | 2.26 E-05 | -4.921 | <0,01 |
| El | -0.0003 | 3.32E-05 | -7.86 | <0,01 |
| AIC = 9105 | ||||
| BIC = 9244 | ||||
| Loglik = -4535 | ||||
La tabella 5. Risultatidel modello M ixed-effects. I parametri fissi stimati, i corrispondenti errori standard e le statistiche di insociezione derivate dall'equazione (9).

Figura 2. Grafico residuo derivato dall'equazione (9). Rispetto alla figura 1, è stato osservato un miglioramento significativo nei residui. Clicca qui per visualizzare una versione più grande di questa figura.
La tabella 6 elenca le tre statistiche di previsione dell'equazione (7) e dell'equazione (9). Rispetto al modello di base, le prestazioni del modello lineare a effetti misti sono state significativamente migliorate.
| Modello | Pregiudizi | Rmse | R2 |
| Modello di base | 0.297 | 0.377 | 0.479 |
| Modello ad effetti misti | 0.221 | 0.286 | 0.699 |
La tabella 6. Indici di valutazione del modello di base e del modello lineare degli effetti misti. Dalle tre statistiche di previsione è stato osservato un miglioramento significativo.
Subscription Required. Please recommend JoVE to your librarian.
Discussion
Una questione cruciale per lo sviluppo di modelli ad effetti misti è determinare quali parametri possono essere trattati come effetti casuali e quali dovrebbero essere considerati effettifissi 34,35. Sono stati proposti due metodi. L'approccio più comune è quello di trattare tutti i parametri come effetti casuali e quindi avere il miglior modello selezionato da AIC, BIC, Loglik e LRT. Questo è stato il metodo utilizzato dal nostro studio35. Un'alternativa è adattare modelli di incremento dell'area basale per ogni tracciato campione con regressione OLS. I parametri che hanno un'elevata variabilità e una minore sovrapposizione negli intervalli di confidenza tra i grafici campione tra questi modelli possono essere considerati casuali17.
Per tenere conto dell'eterogeneità e dell'autocorrelazione, sono state introdotte tre funzioni di varianza e tre strutture di autocorrelazione. Coerentemente con i risultati di Calama e Montero17 e Uzoh e Oliver27, la funzione esponenziale e AR(1) sono state determinate rispettivamente come la funzione di varianza ottimale e la struttura di autocorrelazione.
Esistono due metodi più comunemente utilizzati nei programmi software statistici per stimare modelli ad effetti misti: ML e REML17. ML è più flessibile perché i modelli che differiscono nei loro effetti fissi o nei loro effetti casuali possono essere confrontati direttamente. Tuttavia, lo stimatore per la varianza ottenuta da ML è distorto perché ML non tiene conto del fatto che anche l'intercetta e la pendenza sono stimate (invece di essere conosciute per certo). REML è in grado di fornire stime ml superiori. Pertanto, una volta completati i confronti del modello, il metodo REML è stato utilizzato per il raccordo delmodello finale 17,18,36.
In questo studio, abbiamo scoperto che il modello di incremento dell'area basale a singolo albero per P. asperata usando un approccio lineare ad effetti misti rappresentava un miglioramento significativo rispetto al modello di base usando la regressione OLS. I modelli ad effetti misti forniscono uno strumento efficiente per modellare i dati con struttura stocastica gerarchica, rendendoli ampiamente applicabili in campi come l'agricoltura, la biologia, l'economia, la produzione e la geofisica.
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
Gli autori non hanno nulla da rivelare.
Acknowledgments
Questa ricerca è stata finanziata dai Fondi di ricerca fondamentale per le università centrali, numero di sovvenzione 2019GJZL04. Ringraziamo il professor Weisheng Zeng presso l'Academy of Forest Inventory and Planning, National Forestry and Grassland Administration, Cina per aver fornito l'accesso ai dati.
Materials
| Name | Company | Catalog Number | Comments |
| Computer | acer | ||
| Microsoft Office 2013 | |||
| R x64 3.5.1 |
References
- Meng, J., Lu, Y., Ji, Z. Transformation of a Degraded Pinus massoniana Plantation into a Mixed-Species Irregular Forest: Impacts on Stand Structure and Growth in Southern China. Forests. 5 (12), 3199-3221 (2014).
- Sharma, A., Bohn, K., Jose, S., Cropper, W. P. Converting even-aged plantations to uneven-aged stand conditions: A simulation analysis of silvicultural regimes with slash pine (Pinus elliottii Engelm). Forest Science. 60 (5), 893-906 (2014).
- Zhu, J., et al. Feasibility of implementing thinning in even-aged Larix olgensis plantations to develop uneven-aged larch–broadleaved mixed forests. Journal of Forest Research. 15 (1), 71-80 (2010).
- Leites, L. P., Robinson, A. P., Crookston, N. L. Accuracy and equivalence testing of crown ratio models and assessment of their impact on diameter growth and basal area increment predictions of two variants of the Forest Vegetation Simulator. Canadian Journal of Forest Research. 39 (3), 655-665 (2009).
- Pretzsch, H. Forest Dynamics, Growth and Yield. , (2009).
- Weiskittel, A. R., et al. Forest growth and yield modeling. Forest Growth & Yield Modeling. 7 (2), 223-233 (2002).
- Burkhart, H. E., Tomé, M. Modeling Forest Trees and Stands. , Springer. Netherlands. (2012).
- Zhang, X. Chinese Academy Of Forestry. A linkage among whole-stand model, individual-tree model and diameter-distribution model. Journal of Forest Science. 56 (56), 600-608 (2010).
- Peng, C. Growth and yield models for uneven-aged stands: past, present and future. Forest Ecology & Management. 132 (2), 259-279 (2000).
- Lhotka, J. M., Loewenstein, E. F. An individual-tree diameter growth model for managed uneven-aged oak-shortleaf pine stands in the Ozark Highlands of Missouri, USA. Forest Ecology & Management. 261 (3), 770-778 (2011).
- Porté, A., Bartelink, H. H. Modelling mixed forest growth: a review of models for forest management. Ecological Modelling. 150 (1), 141-188 (2002).
- Moses, L. E., Gale, L. C., Altmann, J. Methods for analysis of unbalanced, longitudinal, growth data. American Journal of Primatology. 28 (1), 49-59 (2010).
- Biging, G. S. Improved Estimates of Site Index Curves Using a Varying-Parameter Model. Forest Science. 31 (31), 248-259 (1985).
- Kowalchuk, R. K., Keselman, H. J. Mixed-model pairwise multiple comparisons of repeated measures means. Psychological Methods. 6 (3), 282-296 (2001).
- Hayes, A. F., Cai, L. Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior Research Methods. 39 (4), 709-722 (2007).
- Gutzwiller, K. J., Riffell, S. K. Using Statistical Models to Study Temporal Dynamics of Animal-Landscape Relations. , Springer. Boston, MA. (2007).
- Calama, R., Montero, G. Multilevel linear mixed model for tree diameter increment in stone pine (Pinus pinea): a calibrating approach. 39, (2005).
- Vonesh, E. F., Chinchilli, V. M. Linear and nonlinear models for the analysis of repeated measurements. Journal of Biopharmaceutical Statistics. 18 (4), 595-610 (1996).
- Zobel, J. M., Ek, A. R., Burk, T. E. Comparison of Forest Inventory and Analysis surveys, basal area models, and fitting methods for the aspen forest type in Minnesota. Forest Ecology & Management. 262 (2), 188-194 (2011).
- Sharma, M., Parton, J. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. Forest Ecology & Management. 249 (3), 187-198 (2007).
- Crecente-Campo, F., Tomé, M., Soares, P., Diéguez-Aranda, U. A generalized nonlinear mixed-effects height–diameter model for Eucalyptus globulus L. in northwestern Spain. Forest Ecology & Management. 259 (5), 943-952 (2010).
- Fu, L., Sharma, R. P., Hao, K., Tang, S. A generalized interregional nonlinear mixed-effects crown width model for Prince Rupprecht larch in northern China. Forest Ecology & Management. 389 (2017), 364-373 (2017).
- Hao, X., Yujun, S., Xinjie, W., Jin, W., Yao, F. Linear mixed-effects models to describe individual tree crown width for China-fir in Fujian Province, southeast China. Plos One. 10 (4), 0122257 (2015).
- Vanderschaaf, C. L., Burkhart, H. E. Comparing methods to estimate Reineke's Maximum Size-Density Relationship species boundary line slope. Forest Science. 53 (3), 435-442 (2007).
- Zhang, L., Bi, H., Gove, J. H., Heath, L. S. A comparison of alternative methods for estimating the self-thinning boundary line. Canadian Journal of Forest Research. 35 (6), 1507-1514 (2005).
- Hart, D. R., Chute, A. S. Estimating von Bertalanffy growth parameters from growth increment data using a linear mixed-effects model, with an application to the sea scallop Placopecten magellanicus. Ices Journal of Marine Science. 66 (9), 2165-2175 (2009).
- Uzoh, F. C. C., Oliver, W. W. Individual tree diameter increment model for managed even-aged stands of ponderosa pine throughout the western United States using a multilevel linear mixed effects model. Forest Ecology & Management. 256 (3), 438-445 (2008).
- Condés, S., Sterba, H. Comparing an individual tree growth model for Pinus halepensis Mill. in the Spanish region of Murcia with yield tables gained from the same area. European Journal of Forest Research. 127 (3), 253-261 (2008).
- Pokharel, B., Dech, J. P. Mixed-effects basal area increment models for tree species in the boreal forest of Ontario, Canada using an ecological land classification approach to incorporate site effects. Forestry. 85 (2), 255-270 (2012).
- Wykoff, W. R. A basal area increment model for individual conifers in the northern Rocky Mountains. Forest Science. 36 (4), 1077-1104 (1990).
- Stage, A. R. Notes: An Expression for the Effect of Aspect, Slope, and Habitat Type on Tree Growth. Forest Science. 22 (4), 457-460 (1976).
- Gregorie, T. G. Generalized Error Structure for Forestry Yield Models. Forest Science. 33 (2), 423-444 (1987).
- Zhao, L., Li, C., Tang, S. Individual-tree diameter growth model for fir plantations based on multi-level linear mixed effects models across southeast China. Journal of Forest Research. 18 (4), 305-315 (2013).
- Hall, D. B., Bailey, R. L. Modeling and Prediction of Forest Growth Variables Based on Multilevel Nonlinear Mixed Models. Forest Science. 47 (3), 311-321 (2001).
- Yang, Y., Huang, S., Meng, S. X., Trincado, G., Vanderschaaf, C. L. A multilevel individual tree basal area increment model for aspen in boreal mixedwood stands : Journal canadien de la recherche forestière. Revue Canadienne De Recherche Forestière. 39 (39), 2203-2214 (2009).
- Pinheiro, J. C., Bates, D. M. Mixed-effects models in S and S-Plus. Publications of the American Statistical Association. 96 (455), 1135-1136 (2000).
