

Summary
混合効果モデルは、林業における階層的確率構造を持つデータを分析するための柔軟で有用なツールであり、森林成長モデルのパフォーマンスを大幅に改善するためにも使用できます。ここでは、線形混合効果モデルに関する情報を合成するプロトコルを提示する。
Abstract
ここでは、中国北西部の新疆省にある779のサンプルプロットから21898 ピセアアスペラタ の木を含むデータセットに基づいて、5年間の基底面積増分の個々の木モデルを開発しました。同じサンプリングユニットからの観測値間の高い相関を防ぐために、確率的変動性を考慮してランダムプロット効果を用いた線形混合効果アプローチを用いてモデルを開発しました。樹木サイズ、競合、サイト条件のインデックスなど、さまざまなツリーレベルおよびスタンドレベル変数が、残留変動性を説明するための固定効果として含まれていました。また、不均一性と自己相関性は、分散関数と自己相関構造を導入して説明した。最適な線形混合効果モデルは、アカイケの情報基準、ベイズ情報基準、対数尤度、尤度比検定など、いくつかの適合統計によって決定されました。その結果、個々の木の基礎面積の増分の有意な変数は、乳房の高さでの直径の逆変換、被験者の木よりも大きい木の基礎面積、ヘクタール当たりの木の数、および標高であることを示した。さらに、分散構造の誤差は指数関数によって最もうまくモデル化され、自己相関は一次自己回帰構造(AR(1)によって有意に補正された。線形混合効果モデルのパフォーマンスは、通常の最小二乗回帰を使用してモデルに対して大幅に改善されました。
Introduction
偶数年の単一培養と比較して、複数の目的を持つ不均一な熟成混合種森林管理は、最近1、2、3の注目を集めています。堅牢な森林管理戦略を策定するためには、異なる管理の選択肢の予測が必要であり、特に複雑な不均一な混合種森林4に対して必要である。森林の成長と収穫モデルは、樹木を予測したり、様々な管理スキーム5、6、7の下で開発と収穫を立ち上げるために広く使用されています。森林の成長と収量モデルは、個別ツリーモデル、サイズクラスモデル、および全スタンド成長モデル6、7、8に分類されます。残念ながら、サイズクラスのモデルと全スタンドモデルは、森林管理の意思決定プロセスをサポートするためにより詳細な説明を必要とする不均一な老朽化した混合種の森林には適していません。このため、樹木の成長と収量モデルは、森林の予測を行う能力が、さまざまな種の組成、構造、および管理戦略9、10、11を持つため、ここ数十年で注目を集めています。
通常の最小二乗(OLS)回帰は、個々の木の成長モデル12、13、14、15の開発に最も一般的に使用される方法です。同じサンプリング単位 (サンプルプロットまたはツリー) 上で一定の時間にわたって繰り返し収集された個々のツリー成長モデルのデータセットは、階層的確率構造を持ち、観測値 10,16の間に独立性の欠如と高い空間的および時間的相関があります。階層的確率構造は、OLS回帰の基本的な仮定、すなわち独立した残差と等分散を伴う正規分布データに違反します。したがって、OLS回帰を使用すると、必然的にこれらのデータ13,14に対するパラメータ推定値の標準誤差の偏った推定値が生成されます。
混合効果モデルは、反復測定データ、縦方向データ、マルチレベルデータなど、複雑な構造を持つデータを分析するための強力なツールです。混合効果モデルは、完全な母集団に共通の固定コンポーネントと、各サンプリングレベルに固有のランダムコンポーネントの両方で構成されます。さらに、混合効果モデルは、非対角分散共分散構造行列17,18,19を定義することにより、空間と時間における不均一性と自己相関性を考慮に入れる。このため、混合効果モデルは、直径高さモデル20、21、クラウンモデル22、23、自己薄化モデル24、25、および成長モデル26、27など、林業で広く使用されています。
ここでの主な目的は、線形混合効果アプローチを用いて、個々の木の基底領域増分モデルを開発することであった。混合効果アプローチが広く適用されることを願っています。
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. データ準備
- 個々の樹木情報(1.3 mの胸の高さで種と直径)とプロット情報(傾斜、傾斜、傾斜、標高)を含むモデリングデータを準備します。この研究では、中国北西部の新疆省の8番目(2009年)と9日(2014年)の中国国有林在庫からデータが得られ、779のサンプルプロットの21,898の観測が含まれています。これらのサンプルプロットは、1Μ(中国の面積は0.067ヘクタールに相当)の大きさの正方形で、4km x 8kmのグリッド上に体系的に配置されています。
注: モデリング (基底領域) 増分のデータには、少なくとも 1 つの成長期間 (つまり、2 つの観測値) が必要です。 - モデルフィッティングに使用されるサンプルプロットのデータの80%をランダムに2つのデータセットに分割し、623のサンプルプロットから17,145個の観測値と、156のサンプルプロットから4,753個の観測値から構成されるモデル検証(モデル検証データセット)の20%で構成されます。使用する主要変数の記述統計は 、表 1に示されています。
注: モデリング手順のこの手順は省略でき、すべてのデータはモデル開発に使用されます。
| 変数 | フィッティングデータ | 検証データ | |||||||
| 分 | 最大 | 意味 | S.D. | 分 | 最大 | 意味 | S.D. | ||
| DBH1 (cm) | 5 | 124.8 | 19.9 | 13.2 | 5 | 101.5 | 19.5 | 13.4 | |
| QMD (cm) | 6.7 | 82.3 | 22.5 | 8.5 | 9.2 | 73.3 | 21.8 | 9.2 | |
| ID (cm) | 0.1 | 14.4 | 1.1 | 1 | 0.1 | 16.9 | 1 | 1.1 | |
| バル (m3) | 0 | 5.2 | 1.7 | 0.9 | 0 | 5.4 | 1.7 | 1 | |
| NT (木/ハ) | 14.9 | 3642 | 1072 | 673.7 | 14.9 | 3418 | 1205 | 829.3 | |
| BA (m2/ha) | 0.1 | 77.5 | 34.2 | 13.9 | 0.1 | 80.6 | 34.5 | 15.3 | |
| EL (m) | 2 | 3302 | 2189 | 340.3 | 1441 | 3380 | 2256 | 308.3 | |
表 1.適合データと検証データの要約統計量 :DBH1: 胸の高さ1.3 m (DBH) での初期直径、 DBH2: 成長5年後に測定された DBH、 QMD:二次平均直径、ID:直径の増分5年間(DBH2 - DBH 1)、BAL:対象木(被験者ツリー:競争指数を計算した木)よりも大きい木の基礎面積、NT:ヘクタールあたりの木の数、BA:ヘクタール当たりの基底面積、EL:標高、S.D.:標準偏差。
2. 基本的なモデル開発
- 参照を参照して、個々のツリーの基礎領域の増分に影響する変数を識別します。
- データに基づいて変数を選択し、計算します。一般に、個々のツリーの基底領域の増分は、ツリー サイズ、競合、およびサイト条件 27、28、29、30 の 3 つの変数グループによって影響を受けます。
- DBH1、DBH1の二乗
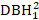 ()、DBH 1 の逆変換 (1/DBH1)、および DBH1 の一般的な対数 (logDBH1)またはそれらの組み合わせなどのツリー サイズの効果を考慮します。
()、DBH 1 の逆変換 (1/DBH1)、および DBH1 の一般的な対数 (logDBH1)またはそれらの組み合わせなどのツリー サイズの効果を考慮します。 - 競争の一面と両側の両方のインデックスのような競争効果を考慮して、ツリーが経験する競争のレベルとスタンド内の社会的地位をより包括的に定量化します。一方的な競合には、BAL と相対密度指数 (RD=DBH1/QMD) が含まれます。二面競争にはNTとBAが含まれます。
注: データが利用可能な場合は、距離依存の競合指数を考慮する必要があります。 - ステージの変換31を使用して、アスペクト (ASP)、傾斜角 (SL)、EL SL、および EL. SL および ASP などのサイト効果を含める必要があることを考慮します。
- DBH1、DBH1の二乗
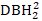 従属変数として log( - +1) ( DBH2の二乗を示す) を選択します。
従属変数として log( - +1) ( DBH2の二乗を示す) を選択します。- ステップワイズ回帰法を使用して基本モデルを開発します。モデルが生物学的に妥当であり、独立変数間で有意な差が生じられるようにしてください。分散膨張係数 (VIF) を利用して多重共線性をチェックします。
- 基本モデルでは、独立変数は p < 0.05 および VIF < 5 のままにしておきます。
- 基本モデルの結果と残差プロットを出力します。ここで作り出された基本モデルは、ミックスエフェクトモデルのさらなる発展の基盤となる。
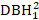 ()、DBH 1 の逆変換 (1/DBH1)、および DBH1 の一般的な対数 (logDBH1)またはそれらの組み合わせなどのツリー サイズの効果を考慮します。
()、DBH 1 の逆変換 (1/DBH1)、および DBH1 の一般的な対数 (logDBH1)またはそれらの組み合わせなどのツリー サイズの効果を考慮します。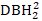
Rソフトウェアのパッケージ"nlme"を用いて線形混合効果モデル開発
- モデル開発データセットを読み取り、パッケージ "nlme" を読み込みます。
>model.development.dataset=read.csv("E:/DATA/JoVE/モデリングデータ.csv"
ヘッダー=真)
>ライブラリ(nlme) - 混合効果モデルを作成するには、ランダム効果としてサンプルプロットを選択します。
- ランダム効果のすべての可能な組み合わせを最尤法(ML)法に適合し、結果を出力します。
>モデル<-lme(Y~1/DBH1+BAL+NT+EL,データ=モデル.開発.データセット、
メソッド="ML"、ランダム=~1|プロット)
>概要(モデル)- ランダム=~1を設定すると、ランダムパラメータに対する切片が指定されます。すべての組み合わせが適合するまで、ランダムステートメントを変更します。例えば、1/DBH1および BAL をランダム・パラメーターとして設定する場合、コードは次のようになります。さらに、適合の過程で、適合モデルの非収束によるエラーをコードが報告する場合があります。
- アカイケの情報基準(AIC)、ベイズ情報基準(BIC)、対数尤度(Loglik)、尤度比検定(LRT)で最適なモデルを選択します。
>anova(モデル.1、モデル.6)
>anova(モデル.6、モデル.23)
>anova(モデル.23、モデル.30) - Riの構造を確認します。Ri32の不均一性と自己相関に対処する。Riは次のように記述されます。
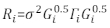 (1)
(1)
ここで、σ 2はモデルの残差分散に等しい未知のスケーリング係数であり、Giは異種関係を表す対角行列であり、Γ iは自己相関を記述する行列である。- 残差が残差プロットからの不均一性であるかどうかを観察します。不均一性がある場合(残差には明確なパターンまたはトレンドがある)、誤差分散構造をモデル化するために、3つの頻繁に使用される分散関数(定数プラスパワー関数、指数関数)を導入します。
>モデル.30.1<-lme(Y~1/DBH1+BAL +NT+EL,データ=モデル.開発.データセット,メソッド=ML",ランダム=〜1/DBH1+BAL+NT|プロット
重み=varConstPower(フォーム=〜フィット(.))
>概要(モデル.30.1)
>モデル.30.2<-lme(Y~1/DBH1+BAL +NT+EL,データ=モデル.開発.データセット,メソッド="ML",ランダム=〜1/DBH1+BAL+NT|プロット
重み=varPower(フォーム=〜フィット(.))
>概要(モデル.30.2)
>モデル.30.3<-lme(Y~1/DBH1+BAL +NT+EL,データ=モデル.開発.データセット,メソッド=ML",ランダム=〜1/DBH1+BAL+NT|プロット
重み=varExp(フォーム=〜フィット(.))
>概要(モデル.30.3) - AIC、BIC、Loglik、および LRT に従って、モデルの最適分散関数を決定します。
>アノバ(モデル.30、モデル.30.1)
>アノバ(モデル.30、モデル.30.2)
>アノバ(モデル.30、モデル.30.3) - 一般的に使用される自己相関構造(複合対称構造(CS)、一次自己回帰構造[AR(1)]、および第1次自己回帰構造と移動平均構造[ARMA(1,1)]の組み合わせ(自己相関を考慮する)を導入します。
>Model.30.3.1<-lme(Y~1/DBH1+BAL+NT+EL,データ=モデル.開発.データセット,メソッド="ML",
ランダム=~1/DBH1+BAL+NT|プロット、ウェイト=varExp(フォーム=〜フィット(.))、コル=コル=コープシム())
>概要(モデル.30.3.1)
>Model.30.3.2<-lme(Y~1/DBH1+BAL+NT+EL,データ=モデル.開発.データセット,メソッド="ML",
ランダム=~1/DBH1+BAL+NT|プロット、ウェイト=varExp(フォーム=〜フィット(.))、コル=corAR1())
>概要(モデル.30.3.2)
>Model.30.3.3<-lme(Y~1/DBH1+BAL+NT+EL,データ=モデル.開発.データセット,メソッド="ML",
ランダム=~1/DBH1+BAL+NT|プロット、ウェイト=varExp(フォーム=〜フィット(.))、コル=コルアルマ(q=1,p=1))
>概要(モデル.30.3.3) - AIC、BIC、Loglik、および LRT に従って最適な自己相関構造を決定します。
>anova(モデル.30.3,モデル.30.3.2)
注意: 不均一性と自己相関がない場合 、Gi と Γi は定義できません。 - 制限された最尤法(REML)法を使用して、混合効果モデルの最終結果を出力します。
>混合.モデル<-lme(Y~1/DBH1+BAL +NT+EL,データ=モデル.開発.データセット,メソッド="REML",ランダム=1/DBH1+BAL+NT|プロット
ウェイト=varExp(フォーム=〜フィット(.))、コル=corAR1())
>サマリー(混合モデル)
- 残差が残差プロットからの不均一性であるかどうかを観察します。不均一性がある場合(残差には明確なパターンまたはトレンドがある)、誤差分散構造をモデル化するために、3つの頻繁に使用される分散関数(定数プラスパワー関数、指数関数)を導入します。
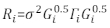 (1)
(1)4. バイアス補正
- 対数スケールの最終モデルを使用して、基底領域増分の予測値を元のスケールに変換します。ただし、このような対数変換モデルからの予測値の線形逆変換は、関連するログ変換バイアスを生成します。対数偏差に対処するために、補正係数が得られ、予測方程式に統合され、特定のツリーの実際の予測基底面積増分が推定されます[式(2)]:
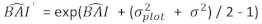 (2)
(2)
ここで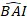 、モデルから基底面積増分の対数値が予測
、モデルから基底面積増分の対数値が予測 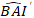 され、対数変換バイアスを補正した後の5年間の基底領域増分の予測後方変換値
され、対数変換バイアスを補正した後の5年間の基底領域増分の予測後方変換値 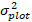 である。プロットにおけるランダム効果からの差異σ 2は残差分散である。
である。プロットにおけるランダム効果からの差異σ 2は残差分散である。 - 基底領域の増分 () を直径増分に変換します。
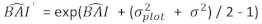 (2)
(2)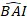 、モデルから基底面積増分の対数値が予測
、モデルから基底面積増分の対数値が予測 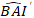 され、対数変換バイアスを補正した後の5年間の基底領域増分の予測後方変換値
され、対数変換バイアスを補正した後の5年間の基底領域増分の予測後方変換値 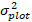 である。プロットにおけるランダム効果からの差異σ 2は残差分散である。
である。プロットにおけるランダム効果からの差異σ 2は残差分散である。5. モデル予測と評価
- セクション 1.2 で作成されたモデル検証データセットを予測用に準備します。
- 線形混合効果モデルを使用して、個々のツリーの基底領域の増分を予測します。ランダム成分は、次の最善の線形偏りのない予測変数を使用して計算されました。
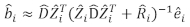 (3)
(3)
ここで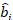 、ランダム成分のベクトルであり
、ランダム成分のベクトルであり 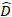 、プロット間変動の分散共分散行列
、プロット間変動の分散共分散行列 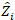 であり、相補的な観測値で作用するランダム成分の設計行列
であり、相補的な観測値で作用するランダム成分の設計行列 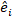 であり、その成分は基底面積増分と固定効果モデルを使用した予測増分の差によって与えられる残留ベクトルです。
であり、その成分は基底面積増分と固定効果モデルを使用した予測増分の差によって与えられる残留ベクトルです。 - 以下の3つの統計指標23,33を用いて、基本モデルと線形混合効果モデルの予測能力を評価し、比較する。
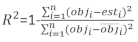 (4)
(4)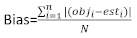 (5)
(5)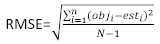 (6)
(6)
ここで obji は基礎面積の増分であり 、esti は予測された基底領域の増分であり、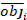 観測値の平均値、N は観測値の数です。
観測値の平均値、N は観測値の数です。
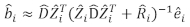 (3)
(3)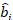 、ランダム成分のベクトルであり
、ランダム成分のベクトルであり 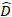 、プロット間変動の分散共分散行列
、プロット間変動の分散共分散行列 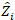 であり、相補的な観測値で作用するランダム成分の設計行列
であり、相補的な観測値で作用するランダム成分の設計行列 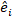 であり、その成分は基底面積増分と固定効果モデルを使用した予測増分の差によって与えられる残留ベクトルです。
であり、その成分は基底面積増分と固定効果モデルを使用した予測増分の差によって与えられる残留ベクトルです。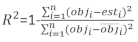 (4)
(4)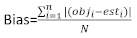 (5)
(5)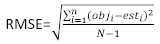 (6)
(6)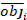 観測値の平均値、N は観測値の数です。
観測値の平均値、N は観測値の数です。Subscription Required. Please recommend JoVE to your librarian.
Representative Results
P.アスペラータの基礎面積増分モデルの基本は、式(7)で表した。パラメータ推定値、対応する標準誤差、および適合しない統計量を表 2に示します。残差プロットは図1に示されています。残差の顕著な不均一性が観察された。 (7)
(7)
| 推定 | 標準エラー | t-テスト | P値 | Vif | |
| Int | 2.41 | 2.26E-02 | 106.78 | <2e-16 | - |
| 1/DBH1 | -5.84 | 7.57E-02 | -77.19 | <2e-16 | 1.12 |
| バル | -0.0954 | 3.34E-03 | -28.54 | <2e-16 | 1.08 |
| Nt | -0.000158 | 4.74E-06 | -33.31 | <2e-16 | 1.12 |
| エル | -0.00011 | 9.07E-06 | -12.13 | <2e-16 | 1.05 |
| AIC = 16789 | |||||
| BIC = 16836 | |||||
| Loglik = -8389 | |||||
表 2.基本的なモデル結果。推定パラメータ、対応する標準誤差、および式(7)から得られる適合値の不適合統計。VIF:分散インフレ率、AIC:アカイケの情報基準、BIC:ベイズ情報基準、Loglik:対数尤度

図 1.方程式(7)から得られた残差プロット。 残差は明確な傾向を有し、すなわち、残差の顕著な不均一性が観察された。 この図の大きなバージョンを表示するには、ここをクリックしてください。
数式(7)には、ランダム効果パラメータの31の可能な組み合わせがありました。フィッティング後、30組の組み合わせが収束に達した(表3)。これらの30の組み合わせの中で、式(8)のモデル30は、最も低いAIC(9083)、最も低いBIC(9207)、最大のLogLik(-4525)、およびLRTが他のモデルと比較して有意に異なっていたので選択された。 (8)
(8)
ここでβ1 ~ β5は固定効果パラメータ、b1 ~ b4はランダム効果パラメータです。
| モデル | ランダムパラメータ | Aic | ビックカメラ | ログリク | Lrt | P値 | ||||
| Int | 1/DBH1 | バル | Nt | エル | ||||||
| 1 | ▲ | 10175 | 10230 | -5081 | ||||||
| 2 | ▲ | 11630 | 11684 | -5808 | ||||||
| 3 | ▲ | 11772 | 11826 | -5879 | ||||||
| 4 | ▲ | 10556 | 10611 | -5271 | ||||||
| 5 | ▲ | 10259 | 10313 | -5123 | ||||||
| 6 | ▲ | ▲ | 9268 | 9338 | -4625 | 911.1 | <.0001 | |||
| (1 対 6) | ||||||||||
| 7 | ▲ | ▲ | 9411 | 9481 | -4697 | |||||
| 8 | ▲ | ▲ | 10179 | 10249 | -5081 | |||||
| 9 | ▲ | ▲ | 10179 | 10249 | -5080 | |||||
| 10 | ▲ | ▲ | 10829 | 10899 | -5406 | |||||
| 11 | ▲ | ▲ | 9532 | 9601 | -4757 | |||||
| 12 | ▲ | ▲ | 9335 | 9405 | -4659 | |||||
| 13 | ▲ | ▲ | 9803 | 9873 | -4892 | |||||
| 14 | ▲ | ▲ | 9465 | 9535 | -4723 | |||||
| 15 | ▲ | ▲ | 10200 | 10270 | -5091 | |||||
| 16 | ▲ | ▲ | ▲ | 非コンバージェンス | ||||||
| 17 | ▲ | ▲ | ▲ | 9271 | 9364 | -4624 | ||||
| 18 | ▲ | ▲ | ▲ | 9274 | 9367 | -4625 | ||||
| 19 | ▲ | ▲ | ▲ | 9417 | 9510 | -4696 | ||||
| 20 | ▲ | ▲ | ▲ | 9417 | 9510 | -4697 | ||||
| 21 | ▲ | ▲ | ▲ | 10184 | 10277 | -5080 | ||||
| 22 | ▲ | ▲ | ▲ | 9332 | 9425 | -4654 | ||||
| 23 | ▲ | ▲ | ▲ | 9132 | 9225 | -4554 | 142.7 | <.0001 | ||
| (23対6) | ||||||||||
| 24 | ▲ | ▲ | ▲ | 9293 | 9386 | -4634 | ||||
| 25 | ▲ | ▲ | ▲ | 9443 | 9536 | -4709 | ||||
| 26 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | |||
| 27 | ▲ | ▲ | ▲ | ▲ | 9086 | 9210 | -4527 | |||
| 28 | ▲ | ▲ | ▲ | ▲ | 9280 | 9404 | -4624 | |||
| 29 | ▲ | ▲ | ▲ | ▲ | 9425 | 9549 | -4696 | |||
| 30 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | 56.8 | <.0001 | |
| (30対23) | ||||||||||
| 31 | ▲ | ▲ | ▲ | ▲ | ▲ | 9091 | 9254 | -4525 | ||
表 3.各線形混合効果モデルの評価インデックス。 ▲:ランダム効果パラメータはフィッティングのために選択されました。LRT: 尤度比検定。
分散関数と相関構造を持つ線形混合効果モデルを 表 4に示します。AIC、BIC、Loglik、およびLRTによると、指数関数とAR(1)がそれぞれ最適分散関数と自己相関構造として選択された。
| モデル | 差異関数 | 相関構造 | Aic | ビックカメラ | ログリク | Lrt | P値 |
| 30 | いいえ | 独立 した | 9083 | 9207 | -4525 | ||
| 30.1 | コンストパワー | 独立 した | 9075 | 9215 | -4520 | 11.8a | 0.0028 |
| 30.2 | 電源 | 独立 した | 9073 | 9205 | -4520 | 11.7a | 6.00E-04 |
| 30.3 | 指数 | 独立 した | 9073 | 9204 | -4519 | 12.3a | 5.00E-04 |
| 30.3.1 | 指数 | Cs | 非コンバージェンス | ||||
| 30.3.2 | 指数 | AR(1) | 9050 | 9189 | -4507 | 24.9b | <.0001 |
| 30.3.3 | 指数 | アルマ(1,1) | 非コンバージェンス | ||||
表 4.線形混合効果の個々ツリー基礎領域増分の比較は、異なる分散関数と異なる相関構造を持つパフォーマンスをモデル 化します。 CS:複合対称構造、AR(1):第1次自己回帰構造、ARMA(1,1):第1次自己回帰構造と移動平均構造の組み合わせ。 尤度 比はモデル30のために計算された; b 尤度比はモデル30.3について計算された。
REML法[式(9)]を用いて、最終的な線形混合効果の個々ツリー基底面積増分モデルを提案した。推定された固定パラメータ、対応する標準誤差、および適合しない統計量を 表5に示します。最終モデルの残差プロットを 図2に示します。残差には有意な改善が見られた。 (9)
(9)
どこ (10)
(10)
| 推定 | 標準エラー | t-テスト | P値 | |
| Int | 2.8086 | 7.99E-02 | 35.14 | <0.01 |
| 1/DBH1 | -6.2402 | 1.56E-01 | -40.01 | <0.01 |
| バル | -0.1324 | 8.07E-03 | -16.41 | <0.01 |
| Nt | -0.0001 | 2.26E-05 | -4.921 | <0.01 |
| エル | -0.0003 | 3.32E-05 | -7.86 | <0.01 |
| AIC = 9105 | ||||
| BIC = 9244 | ||||
| Loglik = -4535 | ||||
表 5.Mixed-エフェクト モデルの結果。 推定された固定パラメータ、対応する標準誤差、および式(9)から得られる適合度の欠けている統計。

図 2.方程式(9)から得られた残差プロット図1と比較して、残差に有意な改善が見られた。この図の大きなバージョンを表示するには、ここをクリックしてください。
表6 は、式(7)と式(9)の3つの予測統計量を示した。基本モデルと比較して、線形混合効果モデルの性能が大幅に向上しました。
| モデル | バイアス | Rmse | R2 |
| 基本モデル | 0.297 | 0.377 | 0.479 |
| 混合効果モデル | 0.221 | 0.286 | 0.699 |
表 6.基本モデルと線形混合効果モデルの評価インデックス。 3つの予測統計から有意な改善が見られた。
Subscription Required. Please recommend JoVE to your librarian.
Discussion
混合効果モデルの開発のための重要な問題は、どのパラメータがランダム効果として扱うことができるか、どのパラメータが固定効果34、35と考えるべきかを決定することです。2つの方法が提案されている。最も一般的なアプローチは、すべてのパラメータをランダムエフェクトとして扱い、AIC、BIC、Loglik、およびLRTによって選択された最良のモデルを持つ方法です。これは我々の研究35で採用された方法でした。代替方法として、OLS 回帰を使用するサンプルプロットごとに基底面積増分モデルを適合させる方法があります。これらのモデル間で、高い変動性と信頼区間の重複が少ないパラメータは、ランダムなもの17と見なすことができます。
不均一性と自己相関を考慮して、3つの分散関数と3つの自己相関構造が導入されました。カラマとモンテロ17 とウゾとオリバー27の結果と一致し、指数関数とAR(1)はそれぞれ最適分散関数と自己相関構造であると判断した。
混合効果モデルを推定する統計ソフトウェアプログラムで最もよく使用される方法は、ML と REML17の 2 種類です。ML は、固定効果またはランダム効果が異なるモデルを直接比較できるため、より柔軟です。しかし、MLが得た分散の推定値は、MLが(特定のために知られているのではなく)同様に切片と傾斜が推定されるという事実を考慮していないため、偏っています。REMLは、優れたML推定値を提供することができます。したがって、モデル比較が完了すると、REML メソッドが最終モデルフィッティング17、18、36に使用されました。
本研究では、線形混合効果アプローチを用いた P.アスペラータ の個々の木基底面積増分モデルが、OLS回帰を用いた基本モデルに対する有意な改善を示すことがわかった。混合効果モデルは、階層構造を持つデータをモデリングするための効率的なツールを提供し、農業、生物学、経済学、製造、地球物理学などの分野で広く適用できます。
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
著者らは開示するものは何もない。
Acknowledgments
この研究は、中央大学のための基礎研究資金によって資金提供されました, 助成金番号 2019GJZL04.中国国立林業・草原局森林インベントリー・アンド・プランニングアカデミーのヴァイシェン・ゼン教授に、データへのアクセスを提供してくれたことに感謝します。
Materials
| Name | Company | Catalog Number | Comments |
| Computer | acer | ||
| Microsoft Office 2013 | |||
| R x64 3.5.1 |
References
- Meng, J., Lu, Y., Ji, Z. Transformation of a Degraded Pinus massoniana Plantation into a Mixed-Species Irregular Forest: Impacts on Stand Structure and Growth in Southern China. Forests. 5 (12), 3199-3221 (2014).
- Sharma, A., Bohn, K., Jose, S., Cropper, W. P. Converting even-aged plantations to uneven-aged stand conditions: A simulation analysis of silvicultural regimes with slash pine (Pinus elliottii Engelm). Forest Science. 60 (5), 893-906 (2014).
- Zhu, J., et al. Feasibility of implementing thinning in even-aged Larix olgensis plantations to develop uneven-aged larch–broadleaved mixed forests. Journal of Forest Research. 15 (1), 71-80 (2010).
- Leites, L. P., Robinson, A. P., Crookston, N. L. Accuracy and equivalence testing of crown ratio models and assessment of their impact on diameter growth and basal area increment predictions of two variants of the Forest Vegetation Simulator. Canadian Journal of Forest Research. 39 (3), 655-665 (2009).
- Pretzsch, H. Forest Dynamics, Growth and Yield. , (2009).
- Weiskittel, A. R., et al. Forest growth and yield modeling. Forest Growth & Yield Modeling. 7 (2), 223-233 (2002).
- Burkhart, H. E., Tomé, M. Modeling Forest Trees and Stands. , Springer. Netherlands. (2012).
- Zhang, X. Chinese Academy Of Forestry. A linkage among whole-stand model, individual-tree model and diameter-distribution model. Journal of Forest Science. 56 (56), 600-608 (2010).
- Peng, C. Growth and yield models for uneven-aged stands: past, present and future. Forest Ecology & Management. 132 (2), 259-279 (2000).
- Lhotka, J. M., Loewenstein, E. F. An individual-tree diameter growth model for managed uneven-aged oak-shortleaf pine stands in the Ozark Highlands of Missouri, USA. Forest Ecology & Management. 261 (3), 770-778 (2011).
- Porté, A., Bartelink, H. H. Modelling mixed forest growth: a review of models for forest management. Ecological Modelling. 150 (1), 141-188 (2002).
- Moses, L. E., Gale, L. C., Altmann, J. Methods for analysis of unbalanced, longitudinal, growth data. American Journal of Primatology. 28 (1), 49-59 (2010).
- Biging, G. S. Improved Estimates of Site Index Curves Using a Varying-Parameter Model. Forest Science. 31 (31), 248-259 (1985).
- Kowalchuk, R. K., Keselman, H. J. Mixed-model pairwise multiple comparisons of repeated measures means. Psychological Methods. 6 (3), 282-296 (2001).
- Hayes, A. F., Cai, L. Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior Research Methods. 39 (4), 709-722 (2007).
- Gutzwiller, K. J., Riffell, S. K. Using Statistical Models to Study Temporal Dynamics of Animal-Landscape Relations. , Springer. Boston, MA. (2007).
- Calama, R., Montero, G. Multilevel linear mixed model for tree diameter increment in stone pine (Pinus pinea): a calibrating approach. 39, (2005).
- Vonesh, E. F., Chinchilli, V. M. Linear and nonlinear models for the analysis of repeated measurements. Journal of Biopharmaceutical Statistics. 18 (4), 595-610 (1996).
- Zobel, J. M., Ek, A. R., Burk, T. E. Comparison of Forest Inventory and Analysis surveys, basal area models, and fitting methods for the aspen forest type in Minnesota. Forest Ecology & Management. 262 (2), 188-194 (2011).
- Sharma, M., Parton, J. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. Forest Ecology & Management. 249 (3), 187-198 (2007).
- Crecente-Campo, F., Tomé, M., Soares, P., Diéguez-Aranda, U. A generalized nonlinear mixed-effects height–diameter model for Eucalyptus globulus L. in northwestern Spain. Forest Ecology & Management. 259 (5), 943-952 (2010).
- Fu, L., Sharma, R. P., Hao, K., Tang, S. A generalized interregional nonlinear mixed-effects crown width model for Prince Rupprecht larch in northern China. Forest Ecology & Management. 389 (2017), 364-373 (2017).
- Hao, X., Yujun, S., Xinjie, W., Jin, W., Yao, F. Linear mixed-effects models to describe individual tree crown width for China-fir in Fujian Province, southeast China. Plos One. 10 (4), 0122257 (2015).
- Vanderschaaf, C. L., Burkhart, H. E. Comparing methods to estimate Reineke's Maximum Size-Density Relationship species boundary line slope. Forest Science. 53 (3), 435-442 (2007).
- Zhang, L., Bi, H., Gove, J. H., Heath, L. S. A comparison of alternative methods for estimating the self-thinning boundary line. Canadian Journal of Forest Research. 35 (6), 1507-1514 (2005).
- Hart, D. R., Chute, A. S. Estimating von Bertalanffy growth parameters from growth increment data using a linear mixed-effects model, with an application to the sea scallop Placopecten magellanicus. Ices Journal of Marine Science. 66 (9), 2165-2175 (2009).
- Uzoh, F. C. C., Oliver, W. W. Individual tree diameter increment model for managed even-aged stands of ponderosa pine throughout the western United States using a multilevel linear mixed effects model. Forest Ecology & Management. 256 (3), 438-445 (2008).
- Condés, S., Sterba, H. Comparing an individual tree growth model for Pinus halepensis Mill. in the Spanish region of Murcia with yield tables gained from the same area. European Journal of Forest Research. 127 (3), 253-261 (2008).
- Pokharel, B., Dech, J. P. Mixed-effects basal area increment models for tree species in the boreal forest of Ontario, Canada using an ecological land classification approach to incorporate site effects. Forestry. 85 (2), 255-270 (2012).
- Wykoff, W. R. A basal area increment model for individual conifers in the northern Rocky Mountains. Forest Science. 36 (4), 1077-1104 (1990).
- Stage, A. R. Notes: An Expression for the Effect of Aspect, Slope, and Habitat Type on Tree Growth. Forest Science. 22 (4), 457-460 (1976).
- Gregorie, T. G. Generalized Error Structure for Forestry Yield Models. Forest Science. 33 (2), 423-444 (1987).
- Zhao, L., Li, C., Tang, S. Individual-tree diameter growth model for fir plantations based on multi-level linear mixed effects models across southeast China. Journal of Forest Research. 18 (4), 305-315 (2013).
- Hall, D. B., Bailey, R. L. Modeling and Prediction of Forest Growth Variables Based on Multilevel Nonlinear Mixed Models. Forest Science. 47 (3), 311-321 (2001).
- Yang, Y., Huang, S., Meng, S. X., Trincado, G., Vanderschaaf, C. L. A multilevel individual tree basal area increment model for aspen in boreal mixedwood stands : Journal canadien de la recherche forestière. Revue Canadienne De Recherche Forestière. 39 (39), 2203-2214 (2009).
- Pinheiro, J. C., Bates, D. M. Mixed-effects models in S and S-Plus. Publications of the American Statistical Association. 96 (455), 1135-1136 (2000).
