

Summary
Modellen met gemengde effecten zijn flexibele en nuttige instrumenten voor het analyseren van gegevens met een hiërarchische stochastische structuur in de bosbouw en kunnen ook worden gebruikt om de prestaties van bosgroeimodellen aanzienlijk te verbeteren. Hier wordt een protocol gepresenteerd dat informatie synthetiseert met betrekking tot lineaire mixed-effects modellen.
Abstract
Hier ontwikkelden we een individueel boommodel van 5-jarige basale gebiedsverhogingen op basis van een dataset met 21898 Picea asperata-bomen van 779 voorbeeldpercelen in de provincie Xinjiang, noordwest-China. Om hoge correlaties tussen waarnemingen van dezelfde bemonsteringseenheid te voorkomen, ontwikkelden we het model met behulp van een lineaire gemengde effectenbenadering met willekeurig ploteffect om rekening te houden met stochastische variabiliteit. Verschillende boom- en standniveauvariabelen, zoals indexen voor boomgrootte, concurrentie en locatieconditie, werden opgenomen als vaste effecten om de resterende variabiliteit te verklaren. Bovendien werden heteroscedasticiteit en autocorrelation beschreven door de introductie van variantiefuncties en autocorrelationstructuren. Het optimale lineaire mixed-effects model werd bepaald door verschillende fit statistieken: Akaike's informatiecriterium, Bayesian informatiecriterium, logaritme waarschijnlijkheid en een waarschijnlijkheidsverhouding test. De resultaten wezen erop dat significante variabelen van de toename van het basale gebied van individuele bomen de omgekeerde transformatie van de diameter op borsthoogte, het basale gebied van bomen groter dan de onderwerpboom, het aantal bomen per hectare en de verhoging waren. Bovendien werden fouten in de variantiestructuur het meest succesvol gemodelleerd door de exponentiële functie en werd de autocorrelation aanzienlijk gecorrigeerd door de eerste orde autoregressieve structuur (AR(1)). De prestaties van het lineaire mixed-effects model werden aanzienlijk verbeterd ten opzichte van het model met behulp van gewone minste kwadraten regressie.
Introduction
In vergelijking met even oude monocultuur heeft het ongelijkberijpte bosbeheer van gemengde soorten met meerdere doelstellingen de laatste tijd meer aandacht gekregen1,2,3. Voorspelling van verschillende beheeralternatieven is noodzakelijk voor het formuleren van robuuste bosbeheerstrategieën, met name voor complexe ongelijkberijpte gemengde soorten bos4. Bosgroei - en opbrengstmodellen zijn op grote schaal gebruikt om de ontwikkeling en oogst van bomen of standen te voorspellen in het kader van verschillende beheersschema 's5,6,7. Bosgroei - en opbrengstmodellen worden ingedeeld in individuele boommodellen, modellen van grootteklasse en groeimodellen voor helestanden 6,7,8. Helaas zijn modellen van grootteklasse en modellen van hele standen niet geschikt voor ongelijkberijpte gemengde soorten bossen, die een meer gedetailleerde beschrijving vereisen om het besluitvormingsproces voor bosbeheer te ondersteunen. Om deze reden hebben individuele boomgroei - en opbrengstmodellen de afgelopen decennia meer aandacht gekregen vanwege hun vermogen om voorspellingen te doen voor bosopstanden met een verscheidenheid aan soortensamenstellingen, structuren en beheerstrategieën9,10,11.
Gewone minst kwadraten (OLS) regressie is de meest gebruikte methode voor de ontwikkeling van individuele boomgroeimodellen12,13,14,15. De datasets voor individuele boomgroeimodellen die herhaaldelijk over een bepaalde tijdsduur op dezelfde bemonsteringseenheid (d.w.z. steekproefplot of boom) worden verzameld , hebben een hiërarchische stochastische structuur, met een gebrek aan onafhankelijkheid en een hoge ruimtelijke en temporele correlatie tussen waarnemingen10,16. De hiërarchische stochastische structuur schendt de fundamentele veronderstellingen van OLS-regressie: namelijk onafhankelijke resten en normaal gedistribueerde gegevens met gelijke verschillen. Daarom levert het gebruik van OLS-regressie onvermijdelijk bevooroordeelde schattingen op van de standaardfout van parameterschattingen voor deze gegevens13,14.
Mixed-effects-modellen bieden een krachtig hulpmiddel voor het analyseren van gegevens met complexe structuren, zoals gegevens voor herhaalde metingen, longitudinale gegevens en gegevens op meerdere niveaus. Modellen met gemengde effecten bestaan uit zowel vaste componenten, gemeenschappelijk voor de volledige populatie, als willekeurige componenten, die specifiek zijn voor elk bemonsteringsniveau. Bovendien houden modellen met gemengde effecten rekening met heteroscedasticiteit en autocorrelation in ruimte en tijd door niet-diagonale variantie-covariantiestructuur matrices17,18,19te definiëren . Om deze reden zijn modellen met gemengde effecten op grote schaal gebruikt in de bosbouw, zoals in modellen met diameterhoogte20,21, kroonmodellen22,23, zelfverdunnende modellen24,25en groeimodellen26,27.
Hier was het belangrijkste doel om een individueel-boom basaal gebiedsverhogingsmodel te ontwikkelen met behulp van een lineaire mixed-effects-benadering. Wij hopen dat de aanpak van gemengde effecten breed kan worden toegepast.
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. Gegevensvoorbereiding
- Stel modelleringsgegevens op, waaronder individuele boominformatie (soort en diameter op borsthoogte op 1,3 m) en perceelinformatie (helling, aspect en hoogte). In deze studie werden de gegevens verkregen van de 8e (2009) en 9e (2014) Chinese Nationale Bosinventaris in de provincie Xinjiang, noordwest China, die 21.898 waarnemingen van 779 steekproefpercelen omvat. Deze voorbeeldpercelen zijn vierkantvormig met een grootte van 1 Mu (Chinese oppervlakte-eenheid gelijk aan 0,067 ha) en zijn systematisch gerangschikt over een raster van 4 km x 8 km.
OPMERKING: Voor gegevens voor modellering (basaal gebied) moet ten minste één groeiperiode nodig zijn (d.w.z. twee waarnemingen). - Verdeel de gegevens willekeurig in twee datasets, met 80% van de gegevens van de voorbeeldpercelen die worden gebruikt voor modelmontage (modelontwikkelingsgegevensset), die bestaat uit 17.145 waarnemingen van 623 voorbeeldpercelen en 20% voor modelvalidatie (modelvalidatiegegevensset) die bestaat uit 4.753 waarnemingen van 156 voorbeeldpercelen. Beschrijvende statistieken voor de gebruikte sleutelvariabelen zijn opgenomen in tabel 1.
OPMERKING: Deze stap van de modelleringsprocedure kan worden weggelaten en alle gegevens worden gebruikt voor modelontwikkeling.
| Variabelen | Passende gegevens | Validatiegegevens | |||||||
| Min | Max | Bedoel | S.d. | Min | Max | Bedoel | S.d. | ||
| DBH1 (cm) | 5 | 124.8 | 19.9 | 13.2 | 5 | 101.5 | 19.5 | 13.4 | |
| QMD (cm) | 6.7 | 82.3 | 22.5 | 8.5 | 9.2 | 73.3 | 21.8 | 9.2 | |
| ID (cm) | 0.1 | 14.4 | 1.1 | 1 | 0.1 | 16.9 | 1 | 1.1 | |
| BAL (m3) | 0 | 5.2 | 1.7 | 0.9 | 0 | 5.4 | 1.7 | 1 | |
| NT (bomen/ha) | 14.9 | 3642 | 1072 | 673.7 | 14.9 | 3418 | 1205 | 829.3 | |
| BA (m2/ha) | 0.1 | 77.5 | 34.2 | 13.9 | 0.1 | 80.6 | 34.5 | 15.3 | |
| EL (m) | 2 | 3302 | 2189 | 340.3 | 1441 | 3380 | 2256 | 308.3 | |
Tabel 1. Overzichtsstatistieken voor montage - en validatiegegevens. DBH1: initiële diameter op borsthoogte bij 1,3 m (DBH), DBH2: DBH gemeten na 5 jaar groei, QMD: kwadratische gemiddelde diameter, ID: diameterverhoging gedurende 5 jaar (DBH2 – DBH1), BAL: het basale gebied van bomen groter dan de onderwerpboom (de onderwerpboom: de boom die de concurrentie-indexen heeft berekend), NT: het aantal bomen per hectare, BA: basaal gebied per hectare, EL: hoogte, S.D.: standaarddeviatie.
2. Basismodelontwikkeling
- Raadpleeg verwijzingen om variabelen te identificeren die van invloed zijn op de toename van het basale gebied tussen afzonderlijke bomen.
- Variabelen selecteren en berekenen op basis van de gegevens. Over het algemeen wordt de toename van het basale gebied tussen afzonderlijke bomen beïnvloed door drie groepen variabelen: boomgrootte, concurrentie en locatievoorwaarde27,28,29,30.
- Denk aan boomgrootte-effecten zoals DBH1, kwadraat van DBH1 (
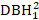 ), de omgekeerde transformatie van DBH1 (1/DBH1) en de gemeenschappelijke logaritme van DBH1 (logDBH1) of combinaties daarvan.
), de omgekeerde transformatie van DBH1 (1/DBH1) en de gemeenschappelijke logaritme van DBH1 (logDBH1) of combinaties daarvan. - Overweeg concurrentie-effecten zoals zowel een- als tweezijdige indices van de concurrentie om het concurrentieniveau van een boom en zijn maatschappelijke positie binnen de stand vollediger te kwantificeren. Eenzijdige concurrentie omvat BAL en de relatieve dichtheidsindex (RD=DBH1/QMD); tweezijdige competitie zijn NT en BA.
OPMERKING: De concurrentie-indexen voor afstandsafhankelijke concurrentie moeten in aanmerking worden genomen als er gegevens beschikbaar zijn. - Overweeg site-effecten zoals aspect (ASP), slope (SL) en EL. SL en ASP moeten worden opgenomen met behulp van stage's transformatie31.
- Denk aan boomgrootte-effecten zoals DBH1, kwadraat van DBH1 (
- Selecteer logboek(
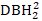 - +1) ( staat voor vierkant van DBH2) als de afhankelijke variabele.
- +1) ( staat voor vierkant van DBH2) als de afhankelijke variabele. - Ontwikkel het basismodel met behulp van de stapsgewijze regressiemethode. Zorg ervoor dat het model biologisch redelijk is en aanzienlijke verschillen vertoont tussen onafhankelijke variabelen. Gebruik de variantie-inflatiefactor (VIF) om te controleren op multicollineariteit.
- Laat de onafhankelijke variabelen met p < 0,05 en VIF < 5 in het basismodel.
- De basismodelresultaten en het restperceel uitvoeren. Het hier geproduceerde basismodel dient als basis voor de verdere ontwikkeling van een mixed-effects model.
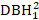 ), de omgekeerde transformatie van DBH1 (1/DBH1) en de gemeenschappelijke logaritme van DBH1 (logDBH1) of combinaties daarvan.
), de omgekeerde transformatie van DBH1 (1/DBH1) en de gemeenschappelijke logaritme van DBH1 (logDBH1) of combinaties daarvan.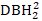 -
- 3. Lineaire mixed-effects modelontwikkeling met het pakket "nlme" in R software
- Lees de modelontwikkelingsdataset en laad het pakket "nlme".
>model.development.dataset=read.csv("E:/DATA/JoVE/modelingdata.csv",
header=WAAR)
>bibliotheek(nlme) - Selecteer voorbeeldplots als willekeurige effecten om het mixed-effects-model te ontwikkelen.
- Plaats alle mogelijke combinaties van willekeurige effecten met de maximale waarschijnlijkheidsmethode (ML) en breng de resultaten uit.
>Model<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset,
method="ML", willekeurig =~1| HET PERCEEL)
>samenvatting(model)- Stel willekeurig =~1 is de interceptie in op willekeurige parameters. Wijzig de willekeurige instructies totdat alle combinaties zijn gemonteerd. Om bijvoorbeeld 1/DBH1 en BAL in te stellen als willekeurige parameters, is de code als volgt: willekeurig =~1/DBH1+BAL-1. Bovendien kunnen de codes tijdens de montage fouten melden als gevolg van de niet-conformiteit van het gemonteerde model.
- Selecteer het beste model op akaike's informatiecriterium (AIC), het Bayesiaanse informatiecriterium (BIC), de logaritmekans (Loglik) en de waarschijnlijkheidsratiotest (LRT).
>anova(Model.1, Model.6)
>anova(Model.6, Model.23)
>anova(Model.23, Model.30) - Bepaal de structuur van Ri. De heteroscedasticiteit en autocorrelation van Ri32 aanpakken. De Ri is als volgt geschreven:
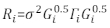 (1)
(1)
waarbij σ2 een onbekende schaalfactor is die gelijk is aan de resterende variantie van het model, G i een diagonale matrix is die heteroscedasticiteit beschrijft, en Γi een matrix is die autocorrelation beschrijft.- Let op de vraag of de restanten heteroscedasticiteit hebben van het restperceel. Als er heteroscedasticiteit is (de resten hebben een duidelijk patroon of trend), introduceert u drie veelgebruikte variantiefuncties - de constante plus-vermogensfunctie, de vermogensfunctie en de exponentiële functie - om de variantiestructuur van fouten te modelleren.
>Model.30.1<-lme (Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",random=~1/DBH1+BAL+NT| Plot
weights=varConstPower(form=~ gemonteerd(.)))
>samenvatting (Model.30.1)
>Model.30.2<-lme (Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",random=~1/DBH1+BAL+NT| Plot
weights=varPower(form=~ gemonteerd(.)))
>samenvatting(Model.30.2)
>Model.30.3<-lme (Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",random=~1/DBH1+BAL+NT| Plot
weights=varExp(form=~ gemonteerd(.)))
>samenvatting (Model.30.3) - Bepaal de beste variantiefunctie voor het model volgens de AIC, BIC, Loglik en LRT.
>anova(Model.30, Model.30.1)
>anova(Model.30, Model.30.2)
>anova(Model.30, Model.30.3) - Introduceer drie veelgebruikte autocorrelation structuren - de samengestelde symmetrie structuur (CS), eerste orde autoregressieve structuur [AR(1)], en een combinatie van eerste orde autoregressieve en voortschrijdende gemiddelde structuren [ARMA(1,1)]— om rekening te houden met autocorrectie.
>Model.30.3.1<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",
willekeurig=~1/DBH1+BAL+NT| PLOT, gewichten=varExp(form=~fitted(.)), corr= corCompSymm())
>samenvatting(Model.30.3.1)
>Model.30.3.2<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",
willekeurig=~1/DBH1+BAL+NT| PLOT,weights=varExp(form=~ fitted(.)), corr=corAR1())
>samenvatting(Model.30.3.2)
>Model.30.3.3<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="ML",
willekeurig=~1/DBH1+BAL+NT| PLOT,weights=varExp(form=~ fitted(.)), corr=corARMA(q=1,p=1))
>samenvatting(Model.30.3.3) - Bepaal de beste autocorrelation structuur volgens de AIC, BIC, Loglik en LRT.
>anova (Model.30.3, Model.30.3.2)
OPMERKING: De Gi en Γi kunnen niet worden gedefinieerd als er geen heteroscedasticiteit en autocorrelation is. - De uiteindelijke resultaten van het mixed-effects-model uitvoeren met behulp van de restricted maximum probability (REML)-methode.
>Mixed.model<-lme (Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="REML",random=~1/DBH1+BAL+NT| Plot
weights=varExp(form=~ fitted(.)), corr=corAR1())
>samenvatting(Mixed.model)
- Let op de vraag of de restanten heteroscedasticiteit hebben van het restperceel. Als er heteroscedasticiteit is (de resten hebben een duidelijk patroon of trend), introduceert u drie veelgebruikte variantiefuncties - de constante plus-vermogensfunctie, de vermogensfunctie en de exponentiële functie - om de variantiestructuur van fouten te modelleren.
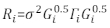 (1)
(1)4. Biascorrectie
- Transformeer de voorspelde waarden van basale gebiedsverhoging met behulp van het uiteindelijke model op een logaritmische schaal naar de oorspronkelijke schaal. Een dergelijke lineaire backtransformatie van voorspelde waarde uit een log-getransformeerd model produceert echter een bijbehorende log-transformatie bias. Om de log-bias aan te pakken, werd een correctiefactor afgeleid en geïntegreerd in de voorspellingsvergelijking, die de werkelijke voorspelde basale gebiedsverhoging voor een bepaalde boom schat [Vergelijking (2)]:
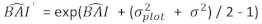 (2)
(2)
waar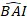 wordt de logaritmische waarde van de toename van het basale gebied ten opzichte van het model voorspeld, terwijl
wordt de logaritmische waarde van de toename van het basale gebied ten opzichte van het model voorspeld, terwijl 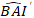 de voorspelde terugtransformatiewaarde van de toename van het basale gebied gedurende 5 jaar na correctie voor log-transformation bias.
de voorspelde terugtransformatiewaarde van de toename van het basale gebied gedurende 5 jaar na correctie voor log-transformation bias. 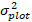 variantie is van willekeurige effecten op plot en σ2 restvariantie is.
variantie is van willekeurige effecten op plot en σ2 restvariantie is. - Converteer basale gebiedsverhoging ( ) naar de diameterverhoging.
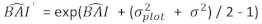 (2)
(2)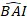 wordt de logaritmische waarde van de toename van het basale gebied ten opzichte van het model voorspeld, terwijl
wordt de logaritmische waarde van de toename van het basale gebied ten opzichte van het model voorspeld, terwijl 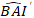 de voorspelde terugtransformatiewaarde van de toename van het basale gebied gedurende 5 jaar na correctie voor log-transformation bias.
de voorspelde terugtransformatiewaarde van de toename van het basale gebied gedurende 5 jaar na correctie voor log-transformation bias. 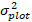 variantie is van willekeurige effecten op plot en σ2 restvariantie is.
variantie is van willekeurige effecten op plot en σ2 restvariantie is.5. Modelvoorspelling en evaluatie
- Bereid de modelvalidatiegegevensset die in sectie 1.2 is geproduceerd voor voorspelling.
- Gebruik het lineaire mixed-effects model om de toename van het basale gebied van de afzonderlijke boom te voorspellen. De willekeurige componenten werden berekend met behulp van de volgende beste lineaire onbevooroordeelde voorspeller:
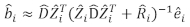 (3)
(3)
waar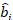 is een vector voor de willekeurige componenten; is de
is een vector voor de willekeurige componenten; is de 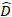 variantie-covariantiematrix voorvariabiliteit tussen percelen;
variantie-covariantiematrix voorvariabiliteit tussen percelen; 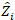 is de ontwerpmatrix voor de willekeurige componenten die bij de aanvullende waarnemingen werken; is de
is de ontwerpmatrix voor de willekeurige componenten die bij de aanvullende waarnemingen werken; is de 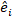 restvector waarvan de componenten worden gegeven door het verschil tussen de basale gebiedsverhogingen en de voorspelde verhogingen met behulp van het model met vaste effecten.
restvector waarvan de componenten worden gegeven door het verschil tussen de basale gebiedsverhogingen en de voorspelde verhogingen met behulp van het model met vaste effecten. - Evalueer en vergelijk het voorspellend vermogen van het basismodel en het lineaire gemengde-effectenmodel aan de hand van de volgende drie statistische indicatoren23,33.
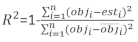 (4)
(4)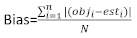 (5)
(5)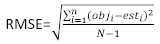 (6)
(6)
waarbij obji de basale gebiedsverhogingen is, esti de voorspelde basale gebiedsverhogingen,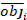 is het gemiddelde van waarnemingen en N het aantal waarnemingen.
is het gemiddelde van waarnemingen en N het aantal waarnemingen.
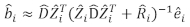 (3)
(3)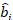 is een vector voor de willekeurige componenten; is de
is een vector voor de willekeurige componenten; is de 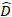 variantie-covariantiematrix voorvariabiliteit tussen percelen;
variantie-covariantiematrix voorvariabiliteit tussen percelen; 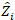 is de ontwerpmatrix voor de willekeurige componenten die bij de aanvullende waarnemingen werken; is de
is de ontwerpmatrix voor de willekeurige componenten die bij de aanvullende waarnemingen werken; is de 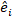 restvector waarvan de componenten worden gegeven door het verschil tussen de basale gebiedsverhogingen en de voorspelde verhogingen met behulp van het model met vaste effecten.
restvector waarvan de componenten worden gegeven door het verschil tussen de basale gebiedsverhogingen en de voorspelde verhogingen met behulp van het model met vaste effecten.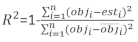 (4)
(4)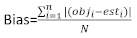 (5)
(5)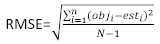 (6)
(6)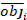 is het gemiddelde van waarnemingen en N het aantal waarnemingen.
is het gemiddelde van waarnemingen en N het aantal waarnemingen.Subscription Required. Please recommend JoVE to your librarian.
Representative Results
Het basisbasisgebiedsverhogingsmodel voor P. asperata werd uitgedrukt als Vergelijking (7). De parameterschattingen, de bijbehorende standaardfouten en het gebrek aan geschikte statistieken zijn weergegeven in tabel 2. Het restperceel is weergegeven in figuur 1. Uitgesproken heteroscedasticiteit van de resten werd waargenomen. (7)
(7)
| Schatting | Standaardfout | t-test | P-waarde | Vif | |
| Int | 2.41 | 2.26E-02 | 106.78 | <2e-16 | - |
| 1/DBH | -5.84 | 7.57E-02 | -77.19 | <2e-16 | 1.12 |
| Bal | -0.0954 | 3.34E-03 | -28.54 | <2e-16 | 1.08 |
| Nt | -0.000158 | 4.74E-06 | -33.31 | <2e-16 | 1.12 |
| El | -0.00011 | 9.07E-06 | -12.13 | <2e-16 | 1.05 |
| AIC = 16789 | |||||
| BIC = 16836 | |||||
| Loglik = -8389 | |||||
Tabel 2. Basismodelresultaten. De geschatte parameters, de bijbehorende standaardfouten en het gebrek aan geschikte statistieken afgeleid van vergelijking (7). VIF: variantie-inflatiefactor, AIC: Akaike's informatiecriterium, BIC: Bayesian informatiecriterium, en Loglik: logaritme waarschijnlijkheid.

Figuur 1. Restperceel afgeleid van vergelijking (7). De residuen hebben een duidelijke trend, d.w.z. er werd een uitgesproken heteroscedasticiteit van de resten waargenomen. Klik hier om een grotere versie van deze figuur te bekijken.
Er waren 31 mogelijke combinaties van random-effects parameters voor Equation (7). Na montage bereikten 30 combinaties convergentie (tabel 3). Van deze 30 combinaties werd model 30 van vergelijking (8) geselecteerd omdat het de laagste AIC (9083), de laagste BIC (9207), de grootste LogLik (-4525) opleverde, en de LRT was aanzienlijk anders in vergelijking met de andere modellen. (8)
(8)
wanneer β1 – β5 de parameters voor vaste effecten zijn en b1 – b4 de parameters voor willekeurige effecten.
| Model | Willekeurige parameters | Aic | Bic | LogLik | Lrt | P-waarde | ||||
| Int | 1/DBH | Bal | Nt | El | ||||||
| 1 | ▲ | 10175 | 10230 | -5081 | ||||||
| 2 | ▲ | 11630 | 11684 | -5808 | ||||||
| 3 | ▲ | 11772 | 11826 | -5879 | ||||||
| 4 | ▲ | 10556 | 10611 | -5271 | ||||||
| 5 | ▲ | 10259 | 10313 | -5123 | ||||||
| 6 | ▲ | ▲ | 9268 | 9338 | -4625 | 911.1 | <.0001 | |||
| (1 tegen 6) | ||||||||||
| 7 | ▲ | ▲ | 9411 | 9481 | -4697 | |||||
| 8 | ▲ | ▲ | 10179 | 10249 | -5081 | |||||
| 9 | ▲ | ▲ | 10179 | 10249 | -5080 | |||||
| 10 | ▲ | ▲ | 10829 | 10899 | -5406 | |||||
| 11 | ▲ | ▲ | 9532 | 9601 | -4757 | |||||
| 12 | ▲ | ▲ | 9335 | 9405 | -4659 | |||||
| 13 | ▲ | ▲ | 9803 | 9873 | -4892 | |||||
| 14 | ▲ | ▲ | 9465 | 9535 | -4723 | |||||
| 15 | ▲ | ▲ | 10200 | 10270 | -5091 | |||||
| 16 | ▲ | ▲ | ▲ | Nonconvergence | ||||||
| 17 | ▲ | ▲ | ▲ | 9271 | 9364 | -4624 | ||||
| 18 | ▲ | ▲ | ▲ | 9274 | 9367 | -4625 | ||||
| 19 | ▲ | ▲ | ▲ | 9417 | 9510 | -4696 | ||||
| 20 | ▲ | ▲ | ▲ | 9417 | 9510 | -4697 | ||||
| 21 | ▲ | ▲ | ▲ | 10184 | 10277 | -5080 | ||||
| 22 | ▲ | ▲ | ▲ | 9332 | 9425 | -4654 | ||||
| 23 | ▲ | ▲ | ▲ | 9132 | 9225 | -4554 | 142.7 | <.0001 | ||
| (23 tegen 6) | ||||||||||
| 24 | ▲ | ▲ | ▲ | 9293 | 9386 | -4634 | ||||
| 25 | ▲ | ▲ | ▲ | 9443 | 9536 | -4709 | ||||
| 26 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | |||
| 27 | ▲ | ▲ | ▲ | ▲ | 9086 | 9210 | -4527 | |||
| 28 | ▲ | ▲ | ▲ | ▲ | 9280 | 9404 | -4624 | |||
| 29 | ▲ | ▲ | ▲ | ▲ | 9425 | 9549 | -4696 | |||
| 30 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | 56.8 | <.0001 | |
| (30 tegen 23) | ||||||||||
| 31 | ▲ | ▲ | ▲ | ▲ | ▲ | 9091 | 9254 | -4525 | ||
Tabel 3. Evaluatie-indexcijfers van elk lineair mixed-effects model. ▲: de parameter random-effects is geselecteerd voor montage; LRT: waarschijnlijkheidsratiotest.
De lineaire modellen met gemengde effecten met variantiefuncties en correlatiestructuren zijn weergegeven in tabel 4. Volgens de AIC, BIC, Loglik en LRT werden de exponentiële functie en AR(1) respectievelijk geselecteerd als de beste variantiefunctie en autocorrelationstructuur.
| Model | Variantie, functie | Correlatiestructuur | Aic | Bic | LogLik | Lrt | P-waarde |
| 30 | Nee | Onafhankelijke | 9083 | 9207 | -4525 | ||
| 30.1 | ConstPower | Onafhankelijke | 9075 | 9215 | -4520 | 11.8a | 0.0028 |
| 30.2 | Macht | Onafhankelijke | 9073 | 9205 | -4520 | 11.7a | 6.00E-04 |
| 30.3 | Exponent | Onafhankelijke | 9073 | 9204 | -4519 | 12.3a | 5.00E-04 |
| 30.3.1 | Exponent | Cs | Nonconvergence | ||||
| 30.3.2 | Exponent | AR(1) | 9050 | 9189 | -4507 | 24,9b | <.0001 |
| 30.3.3 | Exponent | ARMA(1,1) | Nonconvergence | ||||
Tabel 4. Vergelijkingen van de lineaire mixed-effects individuele-boom basale gebied increment modellen prestaties met verschillende variantie functies en verschillende correlatiestructuren. CS: samengestelde symmetriestructuur, AR(1): een autoregressieve structuur van de eerste orde, ARMA(1,1): een combinatie van autoregressieve en voortschrijdende gemiddelde structuren van de eerste orde; voor model 30 is een waarschijnlijkheidsratio berekend; b Waarschijnlijkheidsverhouding werd berekend voor model 30.3.
Het uiteindelijke lineaire mixed-effects individual-tree basale gebiedsverhogingsmodel werd voorgesteld met behulp van de REML-methode [Vergelijking (9)]. De geschatte vaste parameters, de bijbehorende standaardfouten en het gebrek aan geschikte statistieken zijn weergegeven in tabel 5. Het restperceel van het uiteindelijke model is weergegeven in figuur 2. In de restanten werd een significante verbetering waargenomen. (9)
(9)
Waar (10)
(10)
| Schatting | Standaardfout | t-Test | P-waarde | |
| Int | 2.8086 | 7.99E-02 | 35.14 | <0,01 |
| 1/DBH | -6.2402 | 1.56E-01 | -40.01 | <0,01 |
| Bal | -0.1324 | 8.07E-03 | -16.41 | <0,01 |
| Nt | -0.0001 | 2.26E-05 | -4.921 | <0,01 |
| El | -0.0003 | 3.32E-05 | -7.86 | <0,01 |
| AIC = 9105 | ||||
| BIC = 9244 | ||||
| Loglik = -4535 | ||||
Tabel 5. Mixed-effecten model resultaten. De geschatte vaste parameters, de bijbehorende standaardfouten en de onvoldoende geschikte statistieken afgeleid van vergelijking (9).

Figuur 2. Restperceel afgeleid van vergelijking (9). Vergeleken met figuur 1 werd een significante verbetering waargenomen in de resten. Klik hier om een grotere versie van deze figuur te bekijken.
Tabel 6 vermeldde de drie voorspellingsstatistieken van vergelijking (7) en vergelijking (9). In vergelijking met het basismodel werden de prestaties van het lineaire mixed-effects model aanzienlijk verbeterd.
| Model | Bias | RMSE | R2 |
| Basismodel | 0.297 | 0.377 | 0.479 |
| Model met gemengde effecten | 0.221 | 0.286 | 0.699 |
Tabel 6. Evaluatie-indexen van het basismodel en het lineaire mixed-effects model. Uit de drie voorspellingsstatistieken werd een significante verbetering waargenomen.
Subscription Required. Please recommend JoVE to your librarian.
Discussion
Een cruciaal punt voor de ontwikkeling van modellen met gemengde effecten is te bepalen welke parameters als willekeurige effecten kunnen worden behandeld en welke als vaste effecten moeten worden beschouwd34,35. Er zijn twee methoden voorgesteld. De meest voorkomende aanpak is om alle parameters als willekeurige effecten te behandelen en vervolgens het beste model te laten selecteren door AIC, BIC, Loglik en LRT. Dit was de methode die werd gebruikt door onze studie35. Een alternatief is om basale gebiedsverhogingsmodellen te passen voor elk voorbeeldplot met OLS-regressie. Parameters met een hoge variabiliteit en minder overlapping in betrouwbaarheidsintervallen tussen de steekproefpercelen tussen deze modellen kunnen als willekeurige worden beschouwd17.
Om rekening te houden met heteroscedasticiteit en autocorrelation, werden drie variantiefuncties en drie autocorrelationstructuren geïntroduceerd. In overeenstemming met de resultaten van Calama en Montero17 en Uzoh en Oliver27,werden de exponentiële functie en AR(1) bepaald als respectievelijk de optimale variantiefunctie en autocorrelation structuur.
Er zijn twee meest gebruikte methoden in statistische softwareprogramma's om modellen met gemengde effecten te schatten: ML en REML17. ML is flexibeler omdat modellen die verschillen in hun vaste effecten of hun willekeurige effecten direct kunnen worden vergeleken. De schatter voor de door ML verkregen variantie is echter bevooroordeeld omdat ML geen rekening houdt met het feit dat de onderschepping en helling ook worden geschat (in tegenstelling tot zeker bekend zijn). REML kan superieure ML-schattingen geven. Toen de modelvergelijkingen waren voltooid , werd de REML-methode daarom gebruikt voor de definitieve modelmontage17,18,36.
In deze studie ontdekten we dat het individuele basale gebiedsverhogingsmodel voor P. asperata met behulp van een lineaire benadering met gemengde effecten een aanzienlijke verbetering betekende ten opzichte van het basismodel met behulp van OLS-regressie. Modellen met gemengde effecten bieden een efficiënt hulpmiddel voor het modelleren van gegevens met hiërarchische stochastische structuur, waardoor het breed toepasbaar is op gebieden zoals landbouw, biologie, economie, productie en geofysica.
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
De auteurs hebben niets te onthullen.
Acknowledgments
Dit onderzoek is gefinancierd door de Fundamental Research Funds for the Central Universities, subsidienummer 2019GJZL04. We danken professor Weisheng Zeng van de Academy of Forest Inventory and Planning, National Forestry and Grassland Administration, China voor het verstrekken van toegang tot gegevens.
Materials
| Name | Company | Catalog Number | Comments |
| Computer | acer | ||
| Microsoft Office 2013 | |||
| R x64 3.5.1 |
References
- Meng, J., Lu, Y., Ji, Z. Transformation of a Degraded Pinus massoniana Plantation into a Mixed-Species Irregular Forest: Impacts on Stand Structure and Growth in Southern China. Forests. 5 (12), 3199-3221 (2014).
- Sharma, A., Bohn, K., Jose, S., Cropper, W. P. Converting even-aged plantations to uneven-aged stand conditions: A simulation analysis of silvicultural regimes with slash pine (Pinus elliottii Engelm). Forest Science. 60 (5), 893-906 (2014).
- Zhu, J., et al. Feasibility of implementing thinning in even-aged Larix olgensis plantations to develop uneven-aged larch–broadleaved mixed forests. Journal of Forest Research. 15 (1), 71-80 (2010).
- Leites, L. P., Robinson, A. P., Crookston, N. L. Accuracy and equivalence testing of crown ratio models and assessment of their impact on diameter growth and basal area increment predictions of two variants of the Forest Vegetation Simulator. Canadian Journal of Forest Research. 39 (3), 655-665 (2009).
- Pretzsch, H. Forest Dynamics, Growth and Yield. , (2009).
- Weiskittel, A. R., et al. Forest growth and yield modeling. Forest Growth & Yield Modeling. 7 (2), 223-233 (2002).
- Burkhart, H. E., Tomé, M. Modeling Forest Trees and Stands. , Springer. Netherlands. (2012).
- Zhang, X. Chinese Academy Of Forestry. A linkage among whole-stand model, individual-tree model and diameter-distribution model. Journal of Forest Science. 56 (56), 600-608 (2010).
- Peng, C. Growth and yield models for uneven-aged stands: past, present and future. Forest Ecology & Management. 132 (2), 259-279 (2000).
- Lhotka, J. M., Loewenstein, E. F. An individual-tree diameter growth model for managed uneven-aged oak-shortleaf pine stands in the Ozark Highlands of Missouri, USA. Forest Ecology & Management. 261 (3), 770-778 (2011).
- Porté, A., Bartelink, H. H. Modelling mixed forest growth: a review of models for forest management. Ecological Modelling. 150 (1), 141-188 (2002).
- Moses, L. E., Gale, L. C., Altmann, J. Methods for analysis of unbalanced, longitudinal, growth data. American Journal of Primatology. 28 (1), 49-59 (2010).
- Biging, G. S. Improved Estimates of Site Index Curves Using a Varying-Parameter Model. Forest Science. 31 (31), 248-259 (1985).
- Kowalchuk, R. K., Keselman, H. J. Mixed-model pairwise multiple comparisons of repeated measures means. Psychological Methods. 6 (3), 282-296 (2001).
- Hayes, A. F., Cai, L. Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior Research Methods. 39 (4), 709-722 (2007).
- Gutzwiller, K. J., Riffell, S. K. Using Statistical Models to Study Temporal Dynamics of Animal-Landscape Relations. , Springer. Boston, MA. (2007).
- Calama, R., Montero, G. Multilevel linear mixed model for tree diameter increment in stone pine (Pinus pinea): a calibrating approach. 39, (2005).
- Vonesh, E. F., Chinchilli, V. M. Linear and nonlinear models for the analysis of repeated measurements. Journal of Biopharmaceutical Statistics. 18 (4), 595-610 (1996).
- Zobel, J. M., Ek, A. R., Burk, T. E. Comparison of Forest Inventory and Analysis surveys, basal area models, and fitting methods for the aspen forest type in Minnesota. Forest Ecology & Management. 262 (2), 188-194 (2011).
- Sharma, M., Parton, J. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. Forest Ecology & Management. 249 (3), 187-198 (2007).
- Crecente-Campo, F., Tomé, M., Soares, P., Diéguez-Aranda, U. A generalized nonlinear mixed-effects height–diameter model for Eucalyptus globulus L. in northwestern Spain. Forest Ecology & Management. 259 (5), 943-952 (2010).
- Fu, L., Sharma, R. P., Hao, K., Tang, S. A generalized interregional nonlinear mixed-effects crown width model for Prince Rupprecht larch in northern China. Forest Ecology & Management. 389 (2017), 364-373 (2017).
- Hao, X., Yujun, S., Xinjie, W., Jin, W., Yao, F. Linear mixed-effects models to describe individual tree crown width for China-fir in Fujian Province, southeast China. Plos One. 10 (4), 0122257 (2015).
- Vanderschaaf, C. L., Burkhart, H. E. Comparing methods to estimate Reineke's Maximum Size-Density Relationship species boundary line slope. Forest Science. 53 (3), 435-442 (2007).
- Zhang, L., Bi, H., Gove, J. H., Heath, L. S. A comparison of alternative methods for estimating the self-thinning boundary line. Canadian Journal of Forest Research. 35 (6), 1507-1514 (2005).
- Hart, D. R., Chute, A. S. Estimating von Bertalanffy growth parameters from growth increment data using a linear mixed-effects model, with an application to the sea scallop Placopecten magellanicus. Ices Journal of Marine Science. 66 (9), 2165-2175 (2009).
- Uzoh, F. C. C., Oliver, W. W. Individual tree diameter increment model for managed even-aged stands of ponderosa pine throughout the western United States using a multilevel linear mixed effects model. Forest Ecology & Management. 256 (3), 438-445 (2008).
- Condés, S., Sterba, H. Comparing an individual tree growth model for Pinus halepensis Mill. in the Spanish region of Murcia with yield tables gained from the same area. European Journal of Forest Research. 127 (3), 253-261 (2008).
- Pokharel, B., Dech, J. P. Mixed-effects basal area increment models for tree species in the boreal forest of Ontario, Canada using an ecological land classification approach to incorporate site effects. Forestry. 85 (2), 255-270 (2012).
- Wykoff, W. R. A basal area increment model for individual conifers in the northern Rocky Mountains. Forest Science. 36 (4), 1077-1104 (1990).
- Stage, A. R. Notes: An Expression for the Effect of Aspect, Slope, and Habitat Type on Tree Growth. Forest Science. 22 (4), 457-460 (1976).
- Gregorie, T. G. Generalized Error Structure for Forestry Yield Models. Forest Science. 33 (2), 423-444 (1987).
- Zhao, L., Li, C., Tang, S. Individual-tree diameter growth model for fir plantations based on multi-level linear mixed effects models across southeast China. Journal of Forest Research. 18 (4), 305-315 (2013).
- Hall, D. B., Bailey, R. L. Modeling and Prediction of Forest Growth Variables Based on Multilevel Nonlinear Mixed Models. Forest Science. 47 (3), 311-321 (2001).
- Yang, Y., Huang, S., Meng, S. X., Trincado, G., Vanderschaaf, C. L. A multilevel individual tree basal area increment model for aspen in boreal mixedwood stands : Journal canadien de la recherche forestière. Revue Canadienne De Recherche Forestière. 39 (39), 2203-2214 (2009).
- Pinheiro, J. C., Bates, D. M. Mixed-effects models in S and S-Plus. Publications of the American Statistical Association. 96 (455), 1135-1136 (2000).
