

Summary
Mixed effects-modeller er fleksible og nyttige værktøjer til analyse af data med en hierarkisk stokastisk struktur inden for skovbrug og kan også bruges til at forbedre skovvækstmodellernes ydeevne betydeligt. Her præsenteres en protokol, der syntetiserer oplysninger vedrørende lineære blandede effektmodeller.
Abstract
Her har vi udviklet en individuel-træ model af 5-årige basal område stigninger baseret på et datasæt, herunder 21898 Picea asperata træer fra 779 prøve parceller beliggende i Xinjiang-provinsen, nordvest Kina. For at forhindre høje korrelationer mellem observationer fra den samme prøvetagningsenhed udviklede vi modellen ved hjælp af en lineær blandet effektmetode med tilfældig ploteffekt for at tage højde for stokastisk variation. Forskellige træ- og standniveauvariabler, såsom indekser for træstørrelse, konkurrence og tilstand på stedet, blev inkluderet som faste effekter for at forklare restvariationen. Desuden blev heteroscedasticitet og autokorrelation beskrevet ved at indføre variansfunktioner og autokorrelationsstrukturer. Den optimale lineære mixed effects-model blev bestemt af flere fit-statistikker: Akaikes informationskriterium, Bayesian-informationskriterium, logaritme sandsynlighed og en sandsynlighedsforholdstest. Resultaterne viste, at signifikante variabler af individuelle træ basale areal stigning var den omvendte omdannelse af diameter ved brysthøjde, det basale areal af træer større end emnet træet, antallet af træer pr hektar, og elevation. Desuden blev fejl i variansstrukturen modelleret mest af eksponentiel funktion, og autokorrelationen blev i væsentlig grad korrigeret af den autoregressive struktur (AR(1)). Udførelsen af den lineære mixed-effects model blev væsentligt forbedret i forhold til modellen ved hjælp af almindelige mindst firkanter regression.
Introduction
Sammenlignet med lige ældre monokultur har skovforvaltning af ujævne arter af blandede arter med flere mål fået øget opmærksomhed på det seneste1,2,3. Forudsigelse af forskellige forvaltningsalternativer er nødvendig for at formulere robuste skovforvaltningsstrategier, især for komplekse skovsorter af ujævne arter af blandede arter4. Modeller for skovvækst og udbytte er i vid udstrækning blevet anvendt til at forudsige udvikling og høst af træer eller bevoksning under forskellige forvaltningsordninger5,6,7. Skovvækst- og udbyttemodeller klassificeres i individuelle træmodeller, størrelsesklassemodeller og helstandsvækstmodeller6,7,8. Desværre er modeller i størrelsesklassen og helhedsmodeller ikke egnede til ujævne skove af blandede arter, som kræver en mere detaljeret beskrivelse for at støtte beslutningsprocessen for skovforvaltning. Af denne grund har individuelle trævækst- og udbyttemodeller fået øget opmærksomhed gennem de sidste par årtier på grund af deres evne til at lave forudsigelser for skovstande med en række arters sammensætninger, strukturer og forvaltningsstrategier9,10,11.
Almindelig mindst kvadratisk regression (OLS) er den mest anvendte metode til udvikling af individuelle trævækstmodeller12,13,14,15. Datasættene for individuelle trævækstmodeller , der gentagne gange er indsamlet over en bestemt periode på den samme prøvetagningsenhed (dvs. Den hierarkiske stokastiske struktur overtræder ols-regressions grundlæggende antagelser, nemlig uafhængige residualer og normalt distribuerede data med lige store afvigelser. Derfor giver brugen af OLS-regression uundgåeligt partiske estimater af standardfejlen i parameterestimater for disse data13,14.
Mixed effects-modeller er et effektivt værktøj til analyse af data med komplekse strukturer, f.eks. Mixed effects-modeller består af både faste komponenter, der er fælles for hele populationen, og tilfældige komponenter, som er specifikke for hvert prøveudtagningsniveau. Desuden tager modeller med blandede effekter højde for heteroscedasticitet og autokorrelation i tid og rum ved at definere ikke-diagonale varians-kovariansstrukturmatrixer17,18,19. Af denne grund er blandede effekter modeller blevet flittigt brugt i skovbrug, såsom i diameter-højde modeller20,21, krone modeller22,23, selvfortyndende modeller24,25, og vækstmodeller26,27.
Her var hovedformålet at udvikle en individuel-træ basal område tilvækst model ved hjælp af en lineær blandet effekt tilgang. Vi håber, at den blandede virkning kan anvendes i vid udstrækning.
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. Udarbejdelse af data
- Forbered modelleringsdata, som omfatter oplysninger om individuelle træer (art og diameter i brysthøjde ved 1,3 m) og plotoplysninger (hældning, aspekt og højde). I denne undersøgelse blev dataene indhentet fra den 8. (2009) og 9. (2014) kinesiske nationale skovbeholdning i Xinjiang-provinsen, nordvest Kina, som omfatter 21.898 observationer af 779 prøveområder. Disse prøveområder er firkantede med en størrelse på 1 Mu (kinesisk arealenhed svarende til 0,067 ha) og er systematisk arrangeret over et gitter på 4 km x 8 km.
BEMÆRK: Data til modellering (basalområde) stigning kræver mindst én vækstperiode (dvs. to observationer). - Data opdeles tilfældigt i to datasæt, hvor 80 % af dataene fra de prøveområder, der anvendes til modeltilpasning (modeludviklingsdatasæt), som består af 17.145 observationer fra 623 prøveområder og 20 % til modelvalidering (modelvalideringsdatasæt), som består af 4.753 observationer fra 156 prøveområder. De beskrivende statistikker for de anvendte nøglevariabler findes i tabel 1.
BEMÆRK: Dette trin i modelleringsproceduren kan udelades, og alle data bruges til modeludvikling.
| Variabler | Tilpasse data | Valideringsdata | |||||||
| Min | Maks | Mener | S.D. | Min | Maks | Mener | S.D. | ||
| DBH1 (cm) | 5 | 124.8 | 19.9 | 13.2 | 5 | 101.5 | 19.5 | 13.4 | |
| QMD (cm) | 6.7 | 82.3 | 22.5 | 8.5 | 9.2 | 73.3 | 21.8 | 9.2 | |
| Id (cm) | 0.1 | 14.4 | 1.1 | 1 | 0.1 | 16.9 | 1 | 1.1 | |
| Bal (m3) | 0 | 5.2 | 1.7 | 0.9 | 0 | 5.4 | 1.7 | 1 | |
| NT1 træer | 14.9 | 3642 | 1072 | 673.7 | 14.9 | 3418 | 1205 | 829.3 | |
| BA (m2/ha) | 0.1 | 77.5 | 34.2 | 13.9 | 0.1 | 80.6 | 34.5 | 15.3 | |
| EL (m) | 2 | 3302 | 2189 | 340.3 | 1441 | 3380 | 2256 | 308.3 | |
Tabel 1. Oversigtsstatistik for tilpasnings- og valideringsdata. DBH1: oprindelig diameter ved brysthøjde ved 1,3 m (DBH), DBH2: DBH målt efter 5 års vækst QMD: kvadratisk gennemsnitsdiameter, ID: diameterforøgelse i 5 år (DBH2 – DBH1), BAL: det basale areal af træer, der er større end emnetræet (emnetræet: det træ, der blev beregnet konkurrenceindekset), NT: antallet af træer pr. hektar, BA: basalareal pr. hektar, EL: elevation, S.D.: standardafvigelse.
2. Grundlæggende modeludvikling
- Se referencer for at identificere variabler, der påvirker intervallerne i det individuelle basale område.
- Vælg og beregn variabler baseret på dataene. Generelt påvirkes forøgelsen af det individuelle træ basalareal af tre grupper af variabler: træstørrelse, konkurrence og stedtilstand27,28,29,30.
- Overvej virkninger i træstørrelse, f.eks.
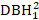
- Overvej konkurrencemæssige virkninger såsom både en- og tosidede konkurrenceindekser for mere omfattende at kvantificere det konkurrenceniveau, som et træ oplever, samt dets sociale position på standen. Ensidig konkurrence omfatter BAL og det relative tæthedsindeks (RD=DBH1/QMD); tosidet konkurrence omfatter NT og BA.
BEMÆRK: Fjernafhængige konkurrenceindekser bør tages i betragtning, hvis der foreligger data. - Overvej webstedseffekter som aspekt (ASP), hældning (SL) og EL. SL og ASP bør medtages ved hjælp af Stage's transformation31.
- Overvej virkninger i træstørrelse, f.eks.
- Vælg log(
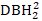 - +1) (angiver kvadrat af DBH2) som den afhængige variabel.
- +1) (angiver kvadrat af DBH2) som den afhængige variabel. - Udarbejd basismodellen ved hjælp af regressionsmetoden trinvist. Sørg for, at modellen er biologisk rimelig og udviser betydelige forskelle mellem uafhængige variabler. Udnyt variansinflationsfaktoren (VIF) til at kontrollere, om der er multikolinearitet.
- Lad de uafhængige variabler med p < 0,05 og VIF < 5 være i basismodellen.
- Output den grundlæggende model resultater og den resterende plot. Den grundlæggende model, der produceres her, tjener som grundlag for videreudviklingen af en mixed effects-model.
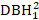
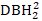 -
- 3. Lineær mixed-effects model udvikling med pakken "nlme" i R-software
- Læs modeludviklingsdatasættet, og indlæs pakken "nlme".
>model.development.dataset=read.csv("E:/DATA/JoVE/modelingdata.csv"
header=SAND)
>bibliotek(nlme) - Vælg stikprøveafbildninger som tilfældige effekter for at udvikle modellen med blandede effekter.
- Monter alle mulige kombinationer af tilfældige effekter med den maksimale sandsynlighed (ML) metode og output resultaterne.
>Model<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset,
metode="ML", tilfældig =~1| OMRÅDE)
>oversigt(model)- Angiv tilfældig =~1 er skæringspunktet til tilfældige parametre. Rediger de tilfældige udsagn, indtil alle kombinationer er monteret. Hvis du f.eks. vil angive 1/DBH1 og BAL som tilfældige parametre, er koden som følger: tilfældig =~1/DBH1+BAL-1. Desuden kan koderne i monteringsprocessen rapportere fejl på grund af den monterede models manglende konvergens.
- Vælg den bedste model efter Akaikes informationskriterium (AIC), Bayesian-informationskriteriet (BIC), logaritme-sandsynligheden (Loglik) og sandsynlighedsforholdtesten (LRT).
>anova(Model.1, Model.6)
>anova(Model.6, Model.23)
>anova(Model.23, Model.30) - Bestem strukturen af Ri. Tag fat på heteroscedasticitet og autokorrelation af Ri32. Ri er skrevet som følger:
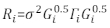 (1)
(1)
hvor σ2 er en ukendt skaleringsfaktor, der er lig med modellens resterende varians, er Gi en diagonal matrix, der beskriver heteroscedasticitet, og Γjeg er en matrix, der beskriver autokorrelation.- Vær opmærksom på, om residualerne har heteroscedasticitet fra det resterende område. Hvis der er heteroscedasticitet (residualerne har et klart mønster eller en klar tendens), skal du introducere tre ofte anvendte variansfunktioner – konstanten plus effektfunktionen, kraftfunktionen og den eksponentielle funktion – for at modellere fejlvariationsstrukturen.
>Model.30.1<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, metode="ML",random=~1/DBH1+BAL+NT| Plot
vægt=varConstPower(form=~ monteret(.)))
>resumé(Model.30.1)
>Model.30.2<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, metode="ML",random=~1/DBH1+BAL+NT| Plot
vægt=varPower(form=~ monteret(.)))
>resumé(Model.30.2)
>Model.30.3<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, metode="ML",random=~1/DBH1+BAL+NT| Plot
vægt=varExp(form=~ monteret(.)))
>oversigt(model.30.3) - Bestem den bedste variansfunktion for modellen i henhold til AIC, BIC, Loglik og LRT.
>anova(Model.30, Model.30.1)
>anova(Model.30, Model.30.2)
>anova(Model.30, Model.30.3) - Introducer tre almindeligt anvendte autokorrelationsstrukturer – den sammensatte symmetristruktur (CS), autoregressiv struktur af første rækkefølge [AR(1)] og en kombination af autoregressive strukturer af første orden og glidende gennemsnit [ARMA(1,1)]– for at tage højde for autokorrelation.
>Model.30.3.1<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.datasæt, metode="ML",
random=~1/DBH1+BAL+NT| PLOT, vægt=varExp(form=~monteret(.)), corr= corCompSymm())
>oversigt(model.30.3.1)
>Model.30.3.2<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, metode="ML",
random=~1/DBH1+BAL+NT| PLOT,vægte=varExp(form=~ monteret(.)), corr=corAR1())
>oversigt(model.30.3.2)
>Model.30.3.3<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, metode="ML",
random=~1/DBH1+BAL+NT| PLOT,vægt=varExp(form=~ monteret(.)), corr=corARMA(q=1,p=1))
>oversigt(model.30.3.3) - Bestem den bedste autokorrelationsstruktur i henhold til AIC, BIC, Loglik og LRT.
>anova(Model.30.3, Model.30.3.2)
BEMÆRK: Gi og Γi kan ikke defineres, hvis der ikke er heteroscedasticitet og autokorrelation. - Output de endelige resultater af mixed effects-modellen ved hjælp af REML-metoden (restricted maximum likelihood).
>Mixed.model<-lme(Y~1/DBH1+BAL+NT+EL,data=model.development.dataset, method="REML",random=~1/DBH1+BAL+NT| Plot
vægt=varExp(form=~ monteret(.)), corr=corAR1())
>oversigt(blandet.model)
- Vær opmærksom på, om residualerne har heteroscedasticitet fra det resterende område. Hvis der er heteroscedasticitet (residualerne har et klart mønster eller en klar tendens), skal du introducere tre ofte anvendte variansfunktioner – konstanten plus effektfunktionen, kraftfunktionen og den eksponentielle funktion – for at modellere fejlvariationsstrukturen.
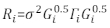 (1)
(1)4. Bias korrektion
- Transformer de forudsagte værdier for forøgelse af basalområdet ved hjælp af den endelige model på en logaritmisk skala til den oprindelige skala. En sådan lineær tilbagetransformation af forudsagt værdi fra en logtransformeret model giver imidlertid en tilknyttet bias for logtransformation. For at håndtere log-bias blev der udledt og integreret en korrektionsfaktor i forudsigelsesligningen, som anslår den faktiske forventede forøgelse af basalområdet for et givet træ [Ligning (2)]:
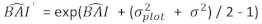 (2)
(2)
hvor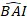 er forudsagt logaritmisk værdi af basale område stigning fra modellen, mens
er forudsagt logaritmisk værdi af basale område stigning fra modellen, mens 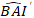 er den forventede tilbage omdannet værdi af basalt areal stigning i 5 år efter korrigere for log-transformation bias
er den forventede tilbage omdannet værdi af basalt areal stigning i 5 år efter korrigere for log-transformation bias 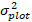 σ.
σ. - Der konverteres en forøgelse af basalområdet ( ) til forøgelsen af diameteren.
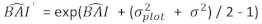 (2)
(2)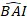 er forudsagt logaritmisk værdi af basale område stigning fra modellen, mens
er forudsagt logaritmisk værdi af basale område stigning fra modellen, mens 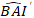 er den forventede tilbage omdannet værdi af basalt areal stigning i 5 år efter korrigere for log-transformation bias
er den forventede tilbage omdannet værdi af basalt areal stigning i 5 år efter korrigere for log-transformation bias 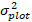 σ.
σ.5. Model forudsigelse og evaluering
- Forbered modelvalideringsdatasættet, der er produceret i afsnit 1.2, til forudsigelse.
- Brug den lineære blandingsmodel til at forudsige forøgelsen af det individuelle basale område. De tilfældige komponenter blev beregnet ved hjælp af følgende bedste lineære upartiske prædiktor:
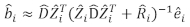 (3)
(3)
hvor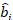 er en vektor for de tilfældige komponenter,
er en vektor for de tilfældige komponenter, 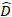 er varians-kovariansmatrixen for variabilitet mellem områderne;
er varians-kovariansmatrixen for variabilitet mellem områderne; 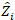
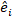
- Vurder og sammenlign den grundlæggende models prædiktive evne og den lineære blandingsmodel ved hjælp af følgende tre statistiske indikatorer23,33.
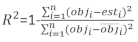 (4)
(4)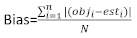 (5)
(5)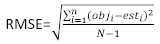 (6)
(6)
hvor obji er de basale arealintervaller, esti er de forventede stigninger i basalområdet,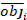 er gennemsnittet af observationer, og N er antallet af observationer.
er gennemsnittet af observationer, og N er antallet af observationer.
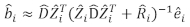 (3)
(3)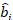 er en vektor for de tilfældige komponenter,
er en vektor for de tilfældige komponenter, 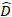 er varians-kovariansmatrixen for variabilitet mellem områderne;
er varians-kovariansmatrixen for variabilitet mellem områderne; 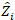
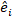
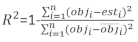 (4)
(4)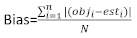 (5)
(5)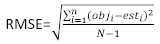 (6)
(6)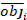 er gennemsnittet af observationer, og N er antallet af observationer.
er gennemsnittet af observationer, og N er antallet af observationer.Subscription Required. Please recommend JoVE to your librarian.
Representative Results
Den grundlæggende model for forøgelse af basalområdet for P. asperata blev udtrykt som Ligning (7). Parameterestimaterne, de tilsvarende standardfejl og statistikkerne over manglende tilpasning fremgår af tabel 2. Restområdet er vist i figur 1. Udtalt heteroscedasticitet af residualerne blev observeret. (7)
(7)
| Skøn | Standardfejl | t-test | P-værdi | VIF | |
| Int | 2.41 | 2.26E-02 | 106.78 | <2e-16 | - |
| 1/DBH1 | -5.84 | 7.57E-02 | -77.19 | <2e-16 | 1.12 |
| Bal | -0.0954 | 3.34E-03 | -28.54 | <2e-16 | 1.08 |
| Nt | -0.000158 | 4.74E-06 | -33.31 | <2e-16 | 1.12 |
| El | -0.00011 | 9.07E-06 | -12.13 | <2e-16 | 1.05 |
| AIC = 16789 | |||||
| BIC = 16836 | |||||
| Loglik = -8389 | |||||
Tabel 2. Grundlæggende modelresultater. De anslåede parametre, deres tilsvarende standardfejl og de manglende fit-statistikker, der er afledt af Equation (7). VIF: variansinflationsfaktor, AIC: Akaikes informationskriterium, BIC: Bayesian informationskriterium, og Loglik: logaritme sandsynlighed.

Figur 1. Restområde afledt af Ligning (7). Residualerne har en klar tendens, dvs. Klik her for at se en større version af dette tal.
Der var 31 mulige kombinationer af random effects parametre for Equation (7). Efter montering nåede 30 kombinationer til konvergens(tabel 3). Blandt disse 30 kombinationer blev Model 30 of Equation (8) valgt, da den gav det laveste AIC (9083), det laveste BIC (9207), det største LogLik (-4525), og LRT var væsentligt anderledes sammenlignet med de andre modeller. (8)
(8)
hvor β1 – β5 er de faste effektparametre og b1 – b4 er random effects-parametrene.
| Model | Tilfældige parametre | Aic | Bic | LogLik | Lrt | P-værdi | ||||
| Int | 1/DBH1 | Bal | Nt | El | ||||||
| 1 | ▲ | 10175 | 10230 | -5081 | ||||||
| 2 | ▲ | 11630 | 11684 | -5808 | ||||||
| 3 | ▲ | 11772 | 11826 | -5879 | ||||||
| 4 | ▲ | 10556 | 10611 | -5271 | ||||||
| 5 | ▲ | 10259 | 10313 | -5123 | ||||||
| 6 | ▲ | ▲ | 9268 | 9338 | -4625 | 911.1 | <.0001 | |||
| (1 mod 6) | ||||||||||
| 7 | ▲ | ▲ | 9411 | 9481 | -4697 | |||||
| 8 | ▲ | ▲ | 10179 | 10249 | -5081 | |||||
| 9 | ▲ | ▲ | 10179 | 10249 | -5080 | |||||
| 10 | ▲ | ▲ | 10829 | 10899 | -5406 | |||||
| 11 | ▲ | ▲ | 9532 | 9601 | -4757 | |||||
| 12 | ▲ | ▲ | 9335 | 9405 | -4659 | |||||
| 13 | ▲ | ▲ | 9803 | 9873 | -4892 | |||||
| 14 | ▲ | ▲ | 9465 | 9535 | -4723 | |||||
| 15 | ▲ | ▲ | 10200 | 10270 | -5091 | |||||
| 16 | ▲ | ▲ | ▲ | Manglende konvergens | ||||||
| 17 | ▲ | ▲ | ▲ | 9271 | 9364 | -4624 | ||||
| 18 | ▲ | ▲ | ▲ | 9274 | 9367 | -4625 | ||||
| 19 | ▲ | ▲ | ▲ | 9417 | 9510 | -4696 | ||||
| 20 | ▲ | ▲ | ▲ | 9417 | 9510 | -4697 | ||||
| 21 | ▲ | ▲ | ▲ | 10184 | 10277 | -5080 | ||||
| 22 | ▲ | ▲ | ▲ | 9332 | 9425 | -4654 | ||||
| 23 | ▲ | ▲ | ▲ | 9132 | 9225 | -4554 | 142.7 | <.0001 | ||
| (23 mod 6) | ||||||||||
| 24 | ▲ | ▲ | ▲ | 9293 | 9386 | -4634 | ||||
| 25 | ▲ | ▲ | ▲ | 9443 | 9536 | -4709 | ||||
| 26 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | |||
| 27 | ▲ | ▲ | ▲ | ▲ | 9086 | 9210 | -4527 | |||
| 28 | ▲ | ▲ | ▲ | ▲ | 9280 | 9404 | -4624 | |||
| 29 | ▲ | ▲ | ▲ | ▲ | 9425 | 9549 | -4696 | |||
| 30 | ▲ | ▲ | ▲ | ▲ | 9083 | 9207 | -4525 | 56.8 | <.0001 | |
| (30 mod 23) | ||||||||||
| 31 | ▲ | ▲ | ▲ | ▲ | ▲ | 9091 | 9254 | -4525 | ||
Tabel 3 . Evalueringsindekser for hver lineær model med blandede effekter. ▲: Parameteren random effects blev valgt til montering; LRT: test af sandsynlighedsforhold.
De lineære blandede effektmodeller med variansfunktioner og korrelationsstrukturer er vist i tabel 4. Ifølge AIC, BIC, Loglik og LRT blev eksponentiel funktion og AR(1) valgt som henholdsvis den bedste variansfunktion og autokorrelationsstruktur.
| Model | Funktionen Afvigelse | Korrelationsstruktur | Aic | Bic | LogLik | Lrt | P-værdi |
| 30 | Nej | Uafhængige | 9083 | 9207 | -4525 | ||
| 30.1 | ConstPower | Uafhængige | 9075 | 9215 | -4520 | 11.8a | 0.0028 |
| 30.2 | Magt | Uafhængige | 9073 | 9205 | -4520 | 11.7a | 6.00E-04 |
| 30.3 | Eksponent | Uafhængige | 9073 | 9204 | -4519 | 12.3a | 5.00E-04 |
| 30.3.1 | Eksponent | Cs | Manglende konvergens | ||||
| 30.3.2 | Eksponent | AR(1) | 9050 | 9189 | -4507 | 24,9b | <.0001 |
| 30.3.3 | Eksponent | ARMA(1,1) | Manglende konvergens | ||||
Tabel 4 . Sammenligninger af de lineære blandede effekter individuelle-træ basal område stigning modeller ydeevne med forskellige varians funktioner og forskellige korrelation strukturer. CS: sammensat symmetristruktur, AR(1): en autoregressiv struktur i første rækkefølge, ARMA(1,1): en kombination af autoregressive og glidende gennemsnitsstrukturer i første rækkefølge; Der blev beregnet et sandsynlighedsforhold for model 30. b Sandsynlighedsforholdet blev beregnet for Model 30.3.
Den endelige lineære model for forøgelse af de enkelte træers basale areal blev foreslået ved hjælp af REML-metoden [Equation (9)]. De anslåede faste parametre, deres tilsvarende standardfejl og statistikkerne over manglende tilpasning fremgår af tabel 5. Restområdet for den endelige model er vist i figur 2. Der blev observeret en betydelig forbedring i residualerne. (9)
(9)
Hvor (10)
(10)
| Skøn | Standardfejl | t-test | P-værdi | |
| Int | 2.8086 | 7.99E-02 | 35.14 | <0,01 |
| 1/DBH1 | -6.2402 | 1.56E-01 | -40.01 | <0,01 |
| Bal | -0.1324 | 8.07E-03 | -16.41 | <0,01 |
| Nt | -0.0001 | 2.26E-05 | -4.921 | <0,01 |
| El | -0.0003 | 3.32E-05 | -7.86 | <0,01 |
| AIC = 9105 | ||||
| BIC = 9244 | ||||
| Loglik = -4535 | ||||
Tabel 5 . Mixed-effekter model resultater. De anslåede faste parametre, deres tilsvarende standardfejl og de manglende fit-statistikker, der er afledt af Equation (9).

Figur 2. Restområde afledt af Ligning (9). Sammenlignet med figur 1 blev der observeret en betydelig forbedring i restprodukterne. Klik her for at se en større version af dette tal.
Tabel 6 viste de tre forudsigelsesstatistikker for Equation (7) og Equation (9). Sammenlignet med basismodellen blev den lineære mixed effects-models ydeevne væsentligt forbedret.
| Model | Bias | RMSE | R2 |
| Grundlæggende model | 0.297 | 0.377 | 0.479 |
| Model med blandede effekter | 0.221 | 0.286 | 0.699 |
Tabel 6 . Evalueringsindekser for basismodellen og den lineære mixed effects-model. Der blev observeret en betydelig forbedring i forhold til de tre forudsigelsesstatistikker.
Subscription Required. Please recommend JoVE to your librarian.
Discussion
Et afgørende spørgsmål for udviklingen af mixed effects-modeller er at afgøre , hvilke parametre der kan behandles som tilfældige effekter , og hvilke der bør betragtes som faste virkninger34,35. Der er foreslået to metoder. Den mest almindelige tilgang er at behandle alle parametre som tilfældige effekter og derefter få den bedste model valgt af AIC, BIC, Loglik og LRT. Dette var den metode, der anvendes af vores undersøgelse35. Et alternativ er at montere basale arealforøgelser modeller for hver prøve plot med OLS regression. Parametre med høj variation og mindre overlapning i konfidensintervaller på tværs af stikprøveområderne mellem disse modeller kan betragtes som tilfældige17.
For at tage højde for heteroscedasticitet og autokorrelation blev der introduceret tre variansfunktioner og tre autokorrelationsstrukturer. I overensstemmelse med resultaterne af Calama og Montero17 og Uzoh og Oliver27blev eksponentiel funktion og AR(1) bestemt til at være henholdsvis den optimale variansfunktion og autokorrelationsstruktur.
Der er to mest anvendte metoder i statistiske softwareprogrammer til at estimere blandede effektmodeller: ML og REML17. ML er mere fleksibel, fordi modeller, der adskiller sig i enten deres faste effekter eller deres tilfældige virkninger, kan sammenlignes direkte. Estimatoren for ml's varians er imidlertid partisk, fordi ML ikke tager højde for, at skæringspunktet og hældningen også estimeres (i modsætning til at være kendt for visse). REML kan give overlegen ML skøn. Derfor, når modelsammenligningerne blev afsluttet, blev REML-metoden brugt til endelig modelmontering17,18,36.
I denne undersøgelse fandt vi, at den individuelle-træ basal område stigning model for P. asperata ved hjælp af en lineær blandet effekt tilgang repræsenterede en betydelig forbedring i forhold til den grundlæggende model ved hjælp af OLS regression. Mixed effects-modeller giver et effektivt værktøj til modellering af data med hierarkisk stokastisk struktur, hvilket gør det bredt anvendeligt inden for områder som landbrug, biologi, økonomi, fremstilling og geofysik.
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
Forfatterne har intet at afsløre.
Acknowledgments
Denne forskning blev finansieret af grundforskningsfondene for de centrale universiteter, tilskudsnummer 2019GJZL04. Vi takker professor Weisheng Zeng på Academy of Forest Inventory and Planning, National Forestry and Grassland Administration, Kina for at give adgang til data.
Materials
| Name | Company | Catalog Number | Comments |
| Computer | acer | ||
| Microsoft Office 2013 | |||
| R x64 3.5.1 |
References
- Meng, J., Lu, Y., Ji, Z. Transformation of a Degraded Pinus massoniana Plantation into a Mixed-Species Irregular Forest: Impacts on Stand Structure and Growth in Southern China. Forests. 5 (12), 3199-3221 (2014).
- Sharma, A., Bohn, K., Jose, S., Cropper, W. P. Converting even-aged plantations to uneven-aged stand conditions: A simulation analysis of silvicultural regimes with slash pine (Pinus elliottii Engelm). Forest Science. 60 (5), 893-906 (2014).
- Zhu, J., et al. Feasibility of implementing thinning in even-aged Larix olgensis plantations to develop uneven-aged larch–broadleaved mixed forests. Journal of Forest Research. 15 (1), 71-80 (2010).
- Leites, L. P., Robinson, A. P., Crookston, N. L. Accuracy and equivalence testing of crown ratio models and assessment of their impact on diameter growth and basal area increment predictions of two variants of the Forest Vegetation Simulator. Canadian Journal of Forest Research. 39 (3), 655-665 (2009).
- Pretzsch, H. Forest Dynamics, Growth and Yield. , (2009).
- Weiskittel, A. R., et al. Forest growth and yield modeling. Forest Growth & Yield Modeling. 7 (2), 223-233 (2002).
- Burkhart, H. E., Tomé, M. Modeling Forest Trees and Stands. , Springer. Netherlands. (2012).
- Zhang, X. Chinese Academy Of Forestry. A linkage among whole-stand model, individual-tree model and diameter-distribution model. Journal of Forest Science. 56 (56), 600-608 (2010).
- Peng, C. Growth and yield models for uneven-aged stands: past, present and future. Forest Ecology & Management. 132 (2), 259-279 (2000).
- Lhotka, J. M., Loewenstein, E. F. An individual-tree diameter growth model for managed uneven-aged oak-shortleaf pine stands in the Ozark Highlands of Missouri, USA. Forest Ecology & Management. 261 (3), 770-778 (2011).
- Porté, A., Bartelink, H. H. Modelling mixed forest growth: a review of models for forest management. Ecological Modelling. 150 (1), 141-188 (2002).
- Moses, L. E., Gale, L. C., Altmann, J. Methods for analysis of unbalanced, longitudinal, growth data. American Journal of Primatology. 28 (1), 49-59 (2010).
- Biging, G. S. Improved Estimates of Site Index Curves Using a Varying-Parameter Model. Forest Science. 31 (31), 248-259 (1985).
- Kowalchuk, R. K., Keselman, H. J. Mixed-model pairwise multiple comparisons of repeated measures means. Psychological Methods. 6 (3), 282-296 (2001).
- Hayes, A. F., Cai, L. Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior Research Methods. 39 (4), 709-722 (2007).
- Gutzwiller, K. J., Riffell, S. K. Using Statistical Models to Study Temporal Dynamics of Animal-Landscape Relations. , Springer. Boston, MA. (2007).
- Calama, R., Montero, G. Multilevel linear mixed model for tree diameter increment in stone pine (Pinus pinea): a calibrating approach. 39, (2005).
- Vonesh, E. F., Chinchilli, V. M. Linear and nonlinear models for the analysis of repeated measurements. Journal of Biopharmaceutical Statistics. 18 (4), 595-610 (1996).
- Zobel, J. M., Ek, A. R., Burk, T. E. Comparison of Forest Inventory and Analysis surveys, basal area models, and fitting methods for the aspen forest type in Minnesota. Forest Ecology & Management. 262 (2), 188-194 (2011).
- Sharma, M., Parton, J. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. Forest Ecology & Management. 249 (3), 187-198 (2007).
- Crecente-Campo, F., Tomé, M., Soares, P., Diéguez-Aranda, U. A generalized nonlinear mixed-effects height–diameter model for Eucalyptus globulus L. in northwestern Spain. Forest Ecology & Management. 259 (5), 943-952 (2010).
- Fu, L., Sharma, R. P., Hao, K., Tang, S. A generalized interregional nonlinear mixed-effects crown width model for Prince Rupprecht larch in northern China. Forest Ecology & Management. 389 (2017), 364-373 (2017).
- Hao, X., Yujun, S., Xinjie, W., Jin, W., Yao, F. Linear mixed-effects models to describe individual tree crown width for China-fir in Fujian Province, southeast China. Plos One. 10 (4), 0122257 (2015).
- Vanderschaaf, C. L., Burkhart, H. E. Comparing methods to estimate Reineke's Maximum Size-Density Relationship species boundary line slope. Forest Science. 53 (3), 435-442 (2007).
- Zhang, L., Bi, H., Gove, J. H., Heath, L. S. A comparison of alternative methods for estimating the self-thinning boundary line. Canadian Journal of Forest Research. 35 (6), 1507-1514 (2005).
- Hart, D. R., Chute, A. S. Estimating von Bertalanffy growth parameters from growth increment data using a linear mixed-effects model, with an application to the sea scallop Placopecten magellanicus. Ices Journal of Marine Science. 66 (9), 2165-2175 (2009).
- Uzoh, F. C. C., Oliver, W. W. Individual tree diameter increment model for managed even-aged stands of ponderosa pine throughout the western United States using a multilevel linear mixed effects model. Forest Ecology & Management. 256 (3), 438-445 (2008).
- Condés, S., Sterba, H. Comparing an individual tree growth model for Pinus halepensis Mill. in the Spanish region of Murcia with yield tables gained from the same area. European Journal of Forest Research. 127 (3), 253-261 (2008).
- Pokharel, B., Dech, J. P. Mixed-effects basal area increment models for tree species in the boreal forest of Ontario, Canada using an ecological land classification approach to incorporate site effects. Forestry. 85 (2), 255-270 (2012).
- Wykoff, W. R. A basal area increment model for individual conifers in the northern Rocky Mountains. Forest Science. 36 (4), 1077-1104 (1990).
- Stage, A. R. Notes: An Expression for the Effect of Aspect, Slope, and Habitat Type on Tree Growth. Forest Science. 22 (4), 457-460 (1976).
- Gregorie, T. G. Generalized Error Structure for Forestry Yield Models. Forest Science. 33 (2), 423-444 (1987).
- Zhao, L., Li, C., Tang, S. Individual-tree diameter growth model for fir plantations based on multi-level linear mixed effects models across southeast China. Journal of Forest Research. 18 (4), 305-315 (2013).
- Hall, D. B., Bailey, R. L. Modeling and Prediction of Forest Growth Variables Based on Multilevel Nonlinear Mixed Models. Forest Science. 47 (3), 311-321 (2001).
- Yang, Y., Huang, S., Meng, S. X., Trincado, G., Vanderschaaf, C. L. A multilevel individual tree basal area increment model for aspen in boreal mixedwood stands : Journal canadien de la recherche forestière. Revue Canadienne De Recherche Forestière. 39 (39), 2203-2214 (2009).
- Pinheiro, J. C., Bates, D. M. Mixed-effects models in S and S-Plus. Publications of the American Statistical Association. 96 (455), 1135-1136 (2000).
