An example of the annotation process is shown in Figure 2. This case22 describes a presentation of infection by the bacterial pathogen Burkholderia thailandensis. For reference, the relevant portion of this CCR is provided in plain text format in Supplementary File 1; some research findings are also presented in this report and are included for comparison. In practice, converting reports provided in HTML or PDF format to plain text may improve the efficiency and ease of metadata extraction.
Examples of two sets of completed CCR metadata annotations are provided in Table 2. The first of these examples is mock data to illustrate the ideal format of each value, while the second example contains values extracted from a published CCR on a rare condition, acrodermatitis enteropathica23.
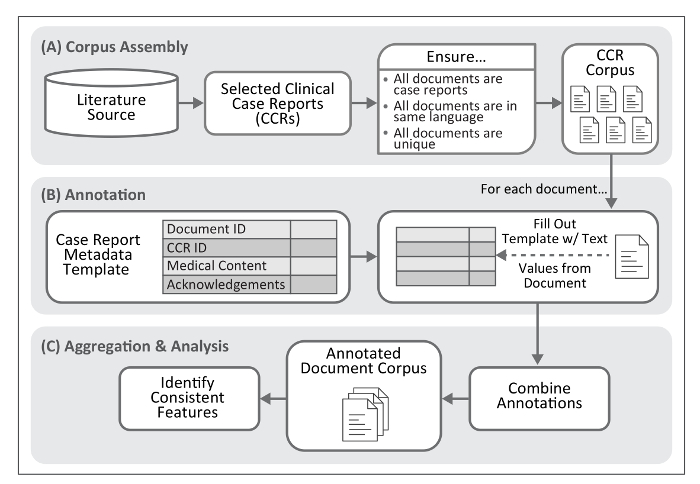
Figure 1. Workflow for Case Report Annotation. The protocol described here provides a method for identification of textual features frequently present within clinical case reports. This process requires assembly of a document corpus. The product of the annotation process, once aggregated into a single file, permits identification of text features associated with medical concepts and their descriptions within case reports. Please click here to view a larger version of this figure.

Figure 2. Identification of Concept-Specific Text in a Clinical Case Report. Beginning with the text of a case report, a manual annotator may progress through the document, identifying segments of text corresponding to each component of the metadata template. Identification features are highlighted in blue. Text corresponding to medical concepts are in red and labeled with their type; all highlighted text in the third column refers to the Pathology type. Please click here to view a larger version of this figure.
| Category | Description | ICD-10 Chapter | ICD-10 Code Range |
| cancer | Any type of cancer or malignant neoplasm. | II | C00-D49 |
| nervous | Any disease of the brain, spine, or nerves. | VI | G00-G99 |
| cardiovascular | Any disease of the heart or vascular system. Does not include hematological diseases. | IX | I00-I99 |
| musculoskeletal and rheumatic | Any disease of the muscles, skeletal system, joints, and connective tissues. | XIII | M00-M99 |
| digestive | Any disease of the gastrointestinal tract and digestive organs, including the liver and pancreas. | XI | K00-K95 |
| obstetrical and gynecological | Any disease relating to pregnancy, childbirth, the female reproductive system, or the breasts. | XIV; XV | O00-O9A; N60-N98 |
| infectious | Any disease causes by infectious microorganisms. | I | A00-B99 |
| respiratory | Any disease of the lungs and respiratory tract. | X | J00-J99 |
| hematologic | Any disease of the blood, bone marrow, lymph nodes, or spleen. | III | D50-D89 |
| kidney and urologic | Any disease of the kidneys or bladder, including the ureters, as well as the male reproductive organs, including the prostate. | XIV | N00-N53; N99 |
| endocrine | Any disease of the endocrine glands, as well as metabolic disorders. | IV | E00-E89 |
| oral and maxillofacial | Any condition involving the mouth, jaws, head, face, or neck. | XI; XIII | K00-K14; M26-M27 |
| eye | Any condition involving the eyes, including blindness. | VII | H00-H59 |
| otorhinolaryngologic | Any condition of the ear, nose, and/or throat. | VIII | H60-H95; J30-J39 |
| skin | Any disease of the skin. | XII | L00-L99 |
| rare | A special category reserved for reports of rare diseases, defined as those impacting fewer than 200,000 individuals in the United States (see https://rarediseases.info.nih.gov/diseases) | NA | NA |
Table 1. Disease Categories for Document Annotation. The categories listed here are those to be used for the Disease System data type in the document metadata template. As each disease presentation may involve multiple organ systems or etiologies, a single clinical case report may correspond to multiple categories. These categories largely follow those used to differentiate sections of the International Statistical Classification of Diseases and Related Health Problems, revision 10 (ICD-10) code system: corresponding ICD-10 chapters and code ranges are provided. Some categories, such as that for oral and maxillofacial disease, correspond to multiple sections of the ICD-10 system.
| Data Type | Example #1 | Example #2 (Cameron and McClain 1986) |
| Document and Annotation Identification | ||
| Internal ID | CCR005 | CCR2000 |
| Annotation Date | Mar 2 2018 | Mar 1 2018 |
| Case Report Identification | ||
| Title | A case of endocarditis. | Ocular histopathology of acrodermatitis enteropathica. |
| Authors | Grant AB;Chang CD | Cameron JD;McClain CJ |
| Year | 2017 | 1986 |
| Journal | World Journal of Medicine and Case Reports | British Journal of Ophthalmology |
| Institution | Department of Medicine, Division of Cardiology, First General Hospital, Boston, Massachusetts, USA | Department of Ophthalmology, University of Minnesota Medical School, Minneapolis, Minnesota 55455 |
| Corresponding Author | Grant AB | Cameron JD |
| PMID | 25555555 | 3756122 |
| DOI | 10.1011/wjmcr.2017.11.001 | NA |
| Link | https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9555555/ | https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1040795/ |
| Language | English | English |
| Medical Content | ||
| Key Words | brucellosis; endocarditis; mitral valve | NA |
| Demography | 37-year-old male | male child |
| Geographic Locations | Florida; Rio de Janeiro, Brazil | NA |
| Life Style | smoker; drinks alcohol occasionally | NA |
| Family History | third of five children of consanguineous parents; younger brother has chronic eczema | NA |
| Social History | construction worker | NA |
| Medical/Surgical History | history of fatigue | 8 pound 9 ounce (3884 g) product of an uncomplicated, full term pregnancy; in good health until age 1 month when he developed a blistering skin rash on his cheeks; rash spread to involve the skin around the eyes, nose, and mouth; skin lesions were also noted on the abdomen and extremities; diarrhoea and failure to thrive; skin biopsy at that time showed parakeratosis typical of acrodermatitis enteropathica; treated over the next six years with intermittent courses of broad spectrum antibiotics, breast milk, and diodoquin; partially responded; developed total alopecia, intermittent acrodermatitis, and intermittent diarrhoea with suboptimal weight gain; spasticity attributed to central nervous system involvement by the ae had developed by 8 months of age; several episodes of cardiopulmonary arrest at 11 months; lack of co-ordination of his vocal cords; tracheostomy; by age 18 months the child developed searching nystagmus associated with bilateral optic atrophy and slight attenuation of retinal vessels as well as signs of psychomotor retardation; bilateral keratoconjunctivitis; skin rash; second skin biopsy performed at age 3 again showed parakeratosis typical for ae; severe skin rash and diarrhoea; bilateral gross anterior corneal opacities were seen which had completely resolved by the time he was reexamined at age five; frequent infections including otitis media, urinary tract infections, and skin infections |
| Disease System | cardiovascular; infectious | digestive; skin; eye; rare |
| Signs and Symptoms | palpitations and dyspnea in the previous week; presented with lethargy, headache, and chills | severe blepharoconjunctivitis and bilateral anterior corneal vascularisation; severe skin rash and diarrhoea; gram-negative bacterial sepsis; skin lesions typical of acrodermatitis enteropathica, absence of thymic tissue, marked degeneration of the optic nerves, chiasm, and optic tracts and extensive cerebellar degeneration |
| Comorbidity | hypertension; hyperlipidemia | NA |
| Diagnostic Techniques and Procedures | Physical examination; electrocardiography; blood cultures | ocular examination; necropsy |
| Diagnosis | Brucella endocarditis | acrodermatitis enteropathica |
| Laboratory Values | increase in c-reactive protein (9 mg/dl); alkaline phosphatase (250 u/l) | NA |
| Pathology | Brucella melitensis was cultured from blood samples | right and left eyes were similar in appearance; corneal epithelium was reduced in thickness to one to three cell layers of flattened squamous epithelial cells over the entire surface of the cornea; all polarity of the epithelium was lost. bowman's membrane could be identified only in the periphery of the right cornea. no bowman's membrane could be identified in the left cornea. neither degenerative nor inflammatory pannus could be identified in either eye; extensive atrophy of the circular and oblique muscles of the ciliary body; some posterior migration of lens capsular epithelium and early cortical degenerative changes; extensive degeneration of the retinal pigment epithelium throughout the posterior pole; retina was attached and showed mild autolytic changes throughout; some preservation of rod and cone outer segments in the posterior pole, however, these structures were completely lost anterior to the equator; extensive loss of the ganglion cell and nerve fibre layers of both eyes; nearly complete atrophy of the disc and adjacent optic nerve |
| Pharmacological Therapy | gentamycin 240 mg/iv/daily | NA |
| Inverventional Therapy | prosthetic valve replacement | NA |
| Patient Outcome Assessment | recovery was uneventful; discharged home | died in 1971 (age 7) |
| Diagnostic Imaging/Videotape Recording | 2;1;0;1 | 7;0;0;0 |
| Relationship to Other Case Reports | 5555555 | 23430849 |
| Relationship with Clinial Trial | NCT05555123 | NA |
| Crosslink with Database | MedlinePlus Health Information: https://medlineplus.gov/ency/article/000597.htm | HighWire – PDF: http://bjo.bmj.com/cgi/pmidlookup?view=long&pmid=3756122; Europe PubMed Central: http://europepmc.org/abstract/MED/3756122; Genetic Alliance: http://www.diseaseinfosearch.org/result/143 |
| Acknowledgements | ||
| Funding Source | National Institutes of Health/National Heart, Lung, and Blood Institute | The Minnesota Lions Club; Research to Prevent Blindness; Veterans Administration; Office of Alcohol and Other Drug Abuse Programming of the State of Minnesota |
| Award Number | R01HL123123 (to AG) | NA |
| Disclosures/Conflict of Interest | Dr. Grant is a paid spokesperson for DrugCo. | NA |
| References | 4 | 27 |
Table 2. Standardized Metadata Template for Clinical Case Reports, with Example Annotations. A set of features common to clinical case reports and facilitating their concept-level annotations is shown here. This template is arranged into three primary sections: Identification, Medical Content, and Acknowledgments, denoting the purpose and additional value afforded by each type of case report feature. This table contains two sets of example annotations, one of a fictionalized case report, and another set derived from a report on the condition acrodermatitis enteropathica23.
Supplementary File 1. Text of a clinical case report (Chang et al. 2017). Please click here to download this file.
