

Summary
染色质免疫沉淀和超高通量测序(芯片起)的组合可以识别并映射在一个给定的组织或细胞系的蛋白质-DNA相互作用。概述是如何产生一个高质量的ChIP随后的测序模板,使用的经验,例如转录因子TCF7L2。
Abstract
芯片测序技术(ChIP-seq的)方法直接提供全基因组的覆盖面,结合染色质免疫沉淀技术(ChIP)和大规模并行测序可以用来识别剧目哺乳动物的DNA序列转录因子在体内的约束。 “下一代”的基因组测序技术提供了1-2个数量级的增加量序列,可以是成本有效的ChIP-seq的方法直接进行有效的分析哺乳动物全基因组覆盖率较老的技术,从而使生成的蛋白质-DNA相互作用。
对于成功的ChIP-seq的方法,必须产生高品质芯片的DNA为模板,以获得最佳的测序成果。的说明是基于经验,最强烈暗示发病机制中的2型糖尿病,即转录因子的转录因子7类2(TCF7L2基因的蛋白产物)。在各种癌症中,这一因素也被牵连。
概述是如何产生的,以高品质的芯片DNA模板来自大肠癌细胞株HCT116通过测序,以确定约束TCF7L2基因,进一步了解其发病机制中的关键作用,建立一个高解析度地图复杂性状。
Introduction
对于许多年一直存在的未满足的需要,以确定约束和受给定的蛋白质的基因组范围,特别是那些在转录因子类基因组。
奥多姆等[1]用染色质免疫沉淀技术(ChIP)结合系统识别占用由预先指定的转录调控因子,在人体的肝脏和胰岛基因的启动子微阵列。随后,约翰逊等人开发了大规模染色质免疫沉淀的基础上直接超高通量DNA测序技术(ChIP-seq的)为了全面映射整个哺乳动物基因组的蛋白-DNA相互作用。测试的情况下,他们在体内的结合映射神经元限制性沉默因子(NRSF)到1946年人类基因组中的位置。数据显示清晰分辨率装订位置(50个碱基对),这有利于双方的i染料溶液的图案和NRSF结合基序识别。这些芯片-Seq数据也有较高的敏感性和特异性和统计的信心(P <10-4),推断新的候选相互作用是重要的属性。
Robertson 等人。3也可用于芯片起,以映射STAT1目标干扰素-γ(IFN-γ)刺激和未刺激的人HeLa S3细胞在体内 。芯片起,使用15.1和1290万唯一对应的序列读取和估计错误发现率小于0.001,他们确定了41,582和11,004公认的STAT1结合区在刺激和未刺激细胞,分别。已知含有STAT1干扰素反应的结合位点4-8的34个位点,芯片起发现有24人(71%)。芯片的seq目标富集序列与已知的STAT1结合基序。比较两个现有的芯片-PCR数据集建议该芯片起的灵敏度为70%和92%,特异度为至少95%之间。此外,它的ChIP-seq的很清楚,同时提供低复杂性和敏感性分析,随着测序深度。
由于这样,“下一代”的基因组测序技术提供了1-2个数量级的增加量的序列,可以产生成本效益比老技术9。因此,芯片的seq方法直接提供的全基因组覆盖率哺乳动物蛋白-DNA相互作用进行有效的分析。
在2006年,强烈关联,在7-2(TCF7L2)与2型糖尿病的基因转录因子的变种被发现10。其他研究者已经独立复制这一发现在不同的种族,有趣的是,从2型糖尿病全基因组关联研究发表在自然 11,12 TCF7L2高达13-15, 科学和其他地方的16,17,的确是最强的协会,这是目前被认为是最重要的2型糖尿病的遗传发现迄今18-20。此外,TCF7L2一直与癌症风险21,22,事实上,这方面变得更加明显8q24染色体位点,揭示了全基因组关联研究,许多癌症,包括大肠癌,被证明是由于极端的上游TCF7L2结合元件驱动MYC基因的转录23,24。因此,有极大的兴趣,确定下游受这个关键转录因子的基因。
基于与TCF7L2作为该方法的一个例子的经验,本文概述了如何产生高品质的芯片的DNA模板。大肠癌细胞株HCT116芯片,为了建立一个高甲阶酚醛树脂为后续测序ution地图基因TCF7L2 25约束的努力产生进一步了解其复杂性状的发病机制中的关键作用。
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1。跨链接染色的
- 100x20mm细胞培养皿中的细胞生长。细胞的量的范围可以从1到10百万个细胞每皿取决于细胞的类型。约2万个细胞就足够一个免疫沉淀。
- 交叉链接的细胞偶尔晃动10分钟,在室温下,用1%的甲醛。
- 淬火通过加入终浓度为125 mM的甘氨酸与孵育5分钟,在室温下交联。
- 洗涤细胞用1X磷酸盐缓冲盐水(PBS)两次,倾析PBS中,然后加入0.2毫升的PBS。
- 收集细胞用塑料刮板细胞的成离心管。
- 自旋向下的细胞在4℃下以2,000 rpm 5分钟
- 吸出上清液。 SDS裂解缓冲液中重悬细胞(1%SDS,10mM的乙二胺四乙酸(EDTA)的50mM Tris-HCl pH值8.1)的全细胞裂解物,或将其作为一个颗粒的核提取。
- 细胞可以被保存在-80℃或一个可以请立即进行伊利与超声。
2。准备核(继续执行步骤3.5全细胞裂解液)
- 用1X蛋白酶抑制剂的每个实验中,补充细胞裂解缓冲液(5mM的筒pH为8.0,85 mM的氯化钾,0.5%NP-40)。
- 解冻细胞沉淀重悬细胞裂解液颗粒体积约10倍。
- DOUNCE均化10倍杵,然后在冰上孵育10分钟。
- 在4000转离心样品在4℃5分钟,弃上清,保存核颗粒。
3。超声*
- 热身SDS裂解缓冲液和使用蛋白酶抑制剂的缓冲液补充量。
- 在SDS裂解缓冲液悬浮核颗粒(约0.5毫升的缓冲液,每1-10万细胞)
- 在冰上孵育10分钟。
- 添加0.5毫升离心管样品。
- 30秒和45秒使用Misonix的超声波仪,超声湿冰关闭幅度设置为2。可以首先通过尝试不同的循环数(例如,2,4,8,12,16,和20个或更多个周期)来确定理想的片段大小的周期数。可用于不同品牌的超声波破碎,然而,情况会有所不同。实验与数量的周期上的时间和关闭必须进行,以便确定了理想的条件。
- 收集超声检查结果,并做定量分析,每个样品20微升。可以储存在-80℃下的样品的其余部分
- 通过加入30微升的0.1×TE缓冲液稀释20微升的样品。
- 治疗核糖核酸酶1μl的样品在37℃,1小时,2小时,然后加入1μl蛋白酶K和孵化,在62°C。
- 运行20μl的样品在2%琼脂糖凝胶上。
- 然后用QIAquick PCR纯化试剂盒纯化样品的剩余量量化使用的NanoDrop分光光度计。
*本地驰P,microccocal核酸酶消化交替使用剪切的DNA。
4。座琼脂糖珠*
- 如果已经堵塞珠,继续步骤5.1。
- 使用蛋白A或蛋白G琼脂糖。对于5免疫沉淀(IPS),用600微升50%珠浆(300微升珠颗粒)
- 洗了有孔玻璃珠,以800rpm旋转,在4℃,持续1分钟,弃去上清液。加入略超过2毫升的ChIP稀释缓冲液(0.01%SDS,1.2 mM的EDTA,167 mM氯化钠,1.1%的Triton X-100,16.7毫米的Tris-HCl pH为8.1),并混合通过缓慢颠倒试管10X。再次停止旋转,在800rpm,在4℃下1分钟,弃去上清液。重复洗涤2次以上。
- 座有孔玻璃珠,用封闭液在4℃过夜旋转。封闭液的配方参考表1。
5。预清除染色
- 超声处理染色质在冰上解冻。
- 降速12000转f或10分钟,在4°C,然后把冰马上删除SDS(白色颗粒)。
- 收集上清液,弃去沉淀,如果有必要,并结合样品。
- 取出实验所需金额的基础上计算(1-10微克每IP的染色质)。
- 稀质10X芯片的稀释液,辅以蛋白酶抑制剂。
- 加入100μl每个IP封锁珠。
- 在4℃旋转1小时。
6。免疫沉淀
- 停止旋转,样品在800 rpm离心1分钟,将上清转移至新管。
- 降速上清液在800转1分钟,转移到另一个干净的试管。
- 保存20微升上层清液,作为输入控制,在-20°C
- 等分试样的染色质在实验中进行的IP地址的数量。
- 新增2微克抗体染色质每1-10微克到每个样品。
- 孵育过夜4℃旋转。
- 加入100μl的封锁珠每个IP样本。
- 孵育1小时,在4℃下旋转。
- 颗粒的有孔玻璃珠通过降低盘片转速在800rpm,持续1分钟,并丢弃尽可能多的上清液。
- 一次低盐免疫复合物洗涤缓冲液洗珠。每个试管中加入1毫升缓冲液,旋转5-8分钟,在室温下,以800rpm旋转1分钟,然后弃上清。重复与高盐免疫复合物洗涤缓冲液和氯化锂的免疫复合物洗涤缓冲液洗一次,两次,共洗涤5次( 表2)的TE缓冲液。
7。洗脱
- 由前一日的解冻输入样本与洗脱剂进行处理。
- 洗脱缓冲新鲜( 表3)。
- IP地址,并输入控制样品加1-2额外的样品需要足够的洗脱缓冲的预混液。
- 加入100μl洗脱缓冲每个IP样本为15米,并在室温下孵育在旋转。
- ,持续1分钟,在800 rpm的转速下停止旋转,并添加新的管中的上清液。
- 添加另一个珠每管100微升洗脱缓冲液,并在室温孵育15分钟旋转。
- 涡旋混合15秒温育后,在5,000 rpm下旋转1分钟,然后结合上清液与从第一洗脱的上清液。 (请确定没有遗留上清中珠,如果不确定,降速再次上清液1分钟5000转,在一个新的管收集上清。
- 洗脱缓冲液中加入180μl20μl的输入控制样品。
8。反向交叉链接
- 200微升洗脱液和输入控件,添加8微升5 M氯化钠。
- 在水浴中于65℃培养过夜,用封口膜和孵化的密封管。
9。 DNA纯化
- 对待每个样品1小时1微升的核糖核酸酶A在37°C。
- 4μ升的0.5M EDTA,8微升1M的Tris-HCl,混合,然后加入1微升的蛋白酶K在45℃下向每个样品,并培育2小时。
- 用QIAquick PCR纯化试剂盒纯化的样品。样品可以保存在-20℃和PCR检查可以做到在稍后的日期。
*或者,芯片同类的磁珠可以用来代替琼脂糖免疫沉淀部分。
10。 PCR检查
- 用于PCR检查,使用已知的约束感兴趣的蛋白质的不同地区的引物。此外,使用非结合区的引物作为阴性对照。
- 对于该反应的试剂混合。按1:100稀释的输入样本( 表3)。
- 运行反应。 PCR程序:
第1步:94℃3分钟
第2步:94℃20秒
59℃30秒
72℃30秒
(CYCL至少30重复第2步ES)
第3步:72℃2分钟
- 1%琼脂糖凝胶上运行样本。
- 也可确定定量实时PCR富集。
Subscription Required. Please recommend JoVE to your librarian.
Representative Results
已被超声处理的染色质,并用RNA酶和蛋白酶处理后,将样品在2%琼脂糖凝胶上运行的应出示涂抹标本所需的大小的DNA与散装。如果几个不同的周期进行测试,逐渐减少的周期数增加( 图2)的大小应被看作是。
完成后的协议的免疫沉淀部的富集,可以由PCR或实时PCR检查。 PCR样品在琼脂糖凝胶上运行,应该有输入和芯片乐队(使用抗体蛋白的兴趣,这是在这种情况下,TCF7L2)样本车道并没有在大多数的情况下,在一个非常微弱的波段(背景噪声)抗体(负)正结合区域控制车道。对于负结合区域应该有非常微弱或没有带IgG的控制和芯片车道。应该有一个输入道的频带中( 图3)。
图4显示了实时PCR检测同一样品。与前面的图中,应该有一个显着的褶皱在IgG对照样品的ChIP富集的正极结合区。此外,应该有很少富集,在负的结合区看到,如果没有,。

图1。芯片过程的流程图。 点击这里查看大图 。
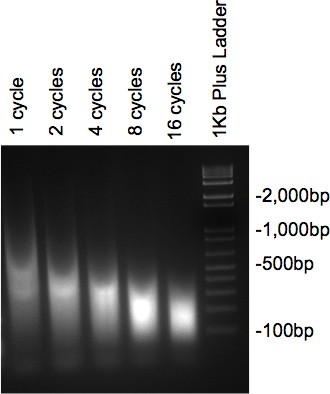
图2。凝胶的DNA超声检查。

图3。 PCR检查芯片。
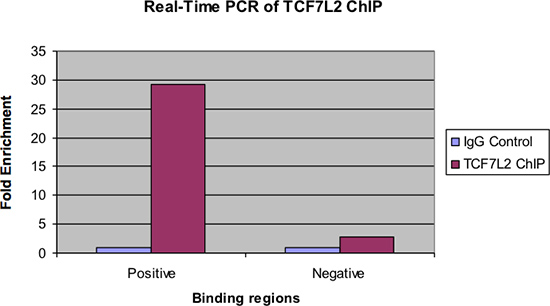
图4。实时PCR TCF7L2芯片。
| 试剂 | 量 |
| 珠颗粒 | 加入300微升 |
| BSA(50毫克/毫升) | 30微升 |
| 100X蛋白酶抑制剂 | 10微升 |
| 芯片稀释液 | 660微升 |
| 总 | 1000微升 |
表1中。配方阻断琼脂糖。
| 缓冲区 | 组件 |
| 低盐免疫复合物的洗涤液 | 0.1%SDS的 1%的Triton X-100的 2毫米EDTA 20毫米的Tris-HCl pH值8.1 150毫米的NaCl |
| 高盐免疫复合物的洗涤液 | 0.1%SDS的 1%的Triton X-100的 2毫米EDTA 20毫米的Tris-HCl pH值8.1 500 mM氯化钠 |
| 氯化锂的免疫复合物的洗涤液 | 0.25 M氯化锂 1%NP-40的 1%脱氧胆酸 1 mM的EDTA 的10mM的Tris-HCl pH 8.1的 |
| TE缓冲液 | 的10mM的Tris-HCl pH 8.1的 1mM EDTA的pH为8.0 |
表2中。芯片洗涤缓冲液。
| 试剂 | 量 |
| 10微升 | |
| 1 M的NaHCO 3 | 20μl的 |
| H 2 O | 170微升 |
表3中。洗脱缓冲液中的一个IP。
| 试剂 | 50μl反应体系 | 20μL反应 |
| 水 | 27微升 | 10.8微升 |
| 5X PCR反应缓冲液 | 10微升 | 4微升 |
| 氯化镁 | 4微升 | 1.6微升 |
| 的dNTP(10毫米) | 1微升 | 0.4微升 |
| 底漆组合(5微米) | 2微升 | 0.8微升 |
| Taq酶(Promega公司热启动) | 1微升</ TD> | 0.4微升 |
| 芯片的DNA | 5微升 | 2微升 |
表4中。 PCR反应体积。
Subscription Required. Please recommend JoVE to your librarian.
Discussion
开展全基因组的蛋白-DNA相互作用协会使用的ChIP-seq的档案现在是可行的,因为已经非常最近展示了与其他转录因子2,3。一个成功的测序结果的关键是一个高品质的染色质免疫沉淀DNA模板的生成。
一旦DNA模板已生成并确定要充分丰富,可以把它在后续测序文库制备。例如,可以使用由供应商提供,Illumina公司的测序文库协议。这个库的大小选择,可以通过凝胶电泳和随后的切除和纯化DNA在约200 - 700-bp的范围内。的体积缩小,并缩小的大小范围的DNA从凝胶纯化收集的目的是为了提高芯片起的位置分辨率。通过丰富的小块输入DNA结合诠释的因素erest,人们会期望该网站的位置将获得分辨率。也提高了更严格的大小选择大小均匀的Illumina的平台上生产的分子菌落。这样的菌落大小均匀,同时也增加了有效的读数。更短的输入DNA大小也产生更强大的菌落的Illumina的平台上,这可能意味着更短的DNA片段,将表示在任何给定的输入样值分布更有效地在最后的序列输出比较长的输入件从相同的分布。
“下一代”的序列分析的生物信息学方法在不断发展,许多厂商,使他们的软件开放源码的进一步细化。可以改造成的DNA片段重叠配置文件读取映射到独特的基因的位置。显着的峰,可以在高度相当于估计的错误发现率确定由threshholding公司。位置SP可以被用来识别和定位整个人类基因组的DNA结合位点对于一个给定的因素是来自于的频率ecific矩阵这项工作。
但是,我们必须保持谨慎,对于什么因素,要研究用芯片起。在着手进行这样的研究之前,应该评估如果抗体是市场上的芯片设置,是可以使用的,作为一个贫穷的抗体可以对一个人的实验结果有非常不利的影响。此外,应考虑是否存在所研究的蛋白的剪接异构体,事实上,TCF7L2是已知有许多异构体,所以我们特别小心选择始终存在该转录因子在所有主要亚型的氨基酸结合的抗体,该抗体25。
综上所述,染色质免疫沉淀和超高通量测序(芯片起)的组合,可以识别和蛋白质-DNA相互作用,在一个给定的组织或c映射ELL线。我们概述了如何生成一个高品质的芯片后续测序模板。
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
作者宣称,他们有没有竞争经济利益。
Acknowledgments
这项工作是支持学院发展奖由来自费城儿童医院。
Materials
| Name | Company | Catalog Number | Comments |
| QIAquick PCR Purification Kit | Qiagen | 28104 | |
| EZ-ChIP Kit | Millipore | 17-371 | |
| GoTaq Hot Start Polymerase | Promega | M5001 | |
| Misonix Sonicator | Qsonica | XL-2000 | |
| NanoDrop 1000 Spectrophotometer | Thermo-Scientific | ||
| Positive control primer sequences (TCF7L2-1) Forward- 5'-TCGCCCTGTCAATAATCTCC-3' Reverse- 5'-GCTCACCTCCTGTATCTTCG-3' Negative control primer sequences (CTRL-1) Forward-5'-ATGTGGTGTGGCTGTGATGGGAAC-3' Reverse- 5'-CGAGCAATCGGTAAATAGGTCTGG-3' |
|||
References
- Odom, D. T., et al. Control of pancreas and liver gene expression by HNF transcription factors. Science. 303, 1378-1381 (2004).
- Johnson, D. S., Mortazavi, A., Myers, R. M., Wold, B. Genome-wide mapping of in vivo protein-DNA interactions. Science. 316, 1497-1502 (2007).
- Robertson, G., et al. Genome-wide profiles of STAT1 DNA association using chromatin immunoprecipitation and massively parallel sequencing. Nature Methods. 4, 651-657 (2007).
- Reich, N. C., Liu, L.
- Lodige, I., et al. Nuclear export determines the cytokine sensitivity of STAT transcription factors. The Journal of Biological Chemistry. 280, 43087-43099 (2005).
- Schroder, K., Sweet, M. J., Hume, D. A. Signal integration between IFNgamma and TLR signalling pathways in macrophages. Immunobiology. 211, 511-524 (2006).
- Vinkemeier, U. Getting the message across, STAT! Design principles of a molecular signaling circuit. The Journal of Cell Biology. 167, 197-201 (2004).
- Brierley, M. M., Fish, E. N.
- Bentley, D. R.
- Grant, S. F., et al. Variant of transcription factor 7-like 2 (TCF7L2) gene confers risk of type 2 diabetes. Nature Genetics. 38, 320-323 (2006).
- Sladek, R., et al. A genome-wide association study identifies novel risk loci for type 2 diabetes. Nature. 445, 881-885 (2007).
- Wellcome Trust Case Control Consortium. Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature. 447, 661-678 (2007).
- Saxena, R., et al. Genome-wide association analysis identifies loci for type 2 diabetes and triglyceride levels. Science. 316, 1331-1336 (2007).
- Zeggini, E., et al. Replication of genome-wide association signals in UK samples reveals risk loci for type 2 diabetes. Science. 316, 1336-1341 (2007).
- Scott, L. J., et al. A genome-wide association study of type 2 diabetes in Finns detects multiple susceptibility variants. Science. 316, 1341-1345 (2007).
- Steinthorsdottir, V., et al. A variant in CDKAL1 influences insulin response and risk of type 2 diabetes. Nature Genetics. 39, 770-775 (2007).
- Salonen, J. T., et al. Type 2 Diabetes Whole-Genome Association Study in Four Populations: The DiaGen Consortium. American Journal of Human Genetics. 81, 338-345 (2007).
- Zeggini, E., McCarthy, M. I. TCF7L2: the biggest story in diabetes genetics since HLA. Diabetologia. 50, 1-4 (2007).
- Weedon, M. N.
- Hattersley, A. T. Prime suspect: the TCF7L2 gene and type 2 diabetes risk. The Journal of Clinical Investigation. 117, 2077-2079 (2007).
- Yochum, G. S., et al. Serial analysis of chromatin occupancy identifies beta-catenin target genes in colorectal carcinoma cells. Proceedings of the National Academy of Sciences of the United States of America. 104, 3324-3329 (2007).
- Duval, A., Busson-Leconiat, M., Berger, R., Hamelin, R. Assignment of the TCF-4 gene (TCF7L2) to human chromosome band 10q25.3. Cytogenet. Cell Genet. 88, 264-265 (2000).
- Pomerantz, M. M., et al. The 8q24 cancer risk variant rs6983267 shows long-range interaction with MYC in colorectal cancer. Nature Genetics. 41, 882-884 (2009).
- Tuupanen, S., et al. The common colorectal cancer predisposition SNP rs6983267 at chromosome 8q24 confers potential to enhanced Wnt signaling. Nature Genetics. 41, 885-890 (2009).
- Zhao, J., Schug, J., Li, M., Kaestner, K. H., Grant, S. F. Disease-associated loci are significantly over-represented among genes bound by transcription factor 7-like 2 (TCF7L2) in vivo. Diabetologia. 53, 2340-2346 (2010).
- Benjamini, Y., Yekutieli, D. Quantitative trait Loci analysis using the false discovery rate. Genetics. 171, 783-790 (2005).
