


Summary
La combinazione di immunoprecipitazione della cromatina e sequenziamento ultra-high-throughput (ChIP-seq) in grado di identificare e mappare le interazioni proteina-DNA in una determinata linea di tessuti o cellule. Delineato è come generare un modello di chip per la successiva sequenza di alta qualità, utilizzando l'esperienza con il fattore di trascrizione TCF7L2 come esempio.
Abstract
(ChIP-seq) metodi di ChIP-sequencing offrono direttamente la copertura dell'intero genoma, in cui combina immunoprecipitazione della cromatina (ChIP) e il sequenziamento massivamente parallelo può essere utilizzato per identificare il repertorio di sequenze di DNA di mammifero vincolati da fattori di trascrizione in vivo. "Next-generation" tecnologie di sequenziamento del genoma forniscono 1-2 ordini di grandezza della quantità di sequenza che può essere costo-efficace generato più vecchie tecnologie consentendo metodi di ChIP-Seq per fornire direttamente la copertura dell'intero genoma per un efficace profiling dei mammiferi interazioni proteina-DNA.
Per successo approcci ChIP-Seq, si deve generare DNA stampo circuito integrato di alta qualità per ottenere i migliori risultati di sequenziamento. La descrizione è basata attorno esperienza con il prodotto proteico del gene più fortemente implicato nella patogenesi del diabete di tipo 2, cioè il fattore di trascrizione fattore di trascrizione 7-like 2 (TCF7L2). Questo fattore è stato anche implicato in vari tumori.
Delineato è come generare modello di DNA circuito integrato di alta qualità derivato dalla linea cellulare di carcinoma del colon-retto, HCT116, al fine di costruire una mappa ad alta risoluzione attraverso il sequenziamento di determinare i geni legati da TCF7L2, dando una visione più completa per il suo ruolo chiave nella patogenesi di tratti complessi.
Introduction
Per molti anni c'è stato un bisogno insoddisfatto per identificare l'insieme di geni legati e regolata da una proteina determinato genoma, in particolare quelli della classe fattore di trascrizione.
Odom et al. 1 usato immunoprecipitazione della cromatina (ChIP) in combinazione con microarrays promotore per identificare sistematicamente i geni occupati dai regolatori trascrizionali pre-specificati, in fegato umano e di isole pancreatiche. Successivamente, Johnson et al. 2 sviluppato un saggio di immunoprecipitazione della cromatina larga scala basata sul sequenziamento del DNA ultra high throughput diretto (ChIP-seq) per mappare completo interazioni proteina-DNA in interi genomi dei mammiferi. Come banco di prova, hanno mappato in vivo il legame del fattore silenziatore neurone-restrittivo (NRSF) a 1946 posizioni nel genoma umano. I dati visualizzati forte risoluzione di posizione di rilegatura (+ 50 paia di basi), che ha facilitato sia l'isolation di motivi e l'identificazione di motivi NRSF vincolanti. Questi dati di ChIP-Seq avevano anche elevata sensibilità e specificità e confidenza statistica (P <10 -4), proprietà che sono importanti per inferire nuove interazioni candidati.
Robertson et al. 3 utilizzato anche ChIP-seq, al fine di mappare STAT1 obiettivi in interferone-γ (IFN-γ)-stimolato e non stimolate le cellule HeLa S3 umane in vivo. Da Chip-Seq, con 15,1 e 12,9 milioni di sequenza mappata univocamente legge, e un tasso stimato falsa scoperta di meno di 0.001, hanno identificato 41.582 e 11.004 putative regioni STAT1 vincolanti in cellule stimolate e non stimolate, rispettivamente. Dei 34 loci noti per contenere STAT1 interferone-reattiva siti 4-8 vincolante, ChIP-seq trovato 24 (71%). Obiettivi di ChIP-Seq sono stati arricchiti in sequenze simili a note STAT1 motivi di legame. Confronti con due dati di ChIP-PCR esistenti set suggeritiche la sensibilità ChIP-seq era tra il 70% e il 92% e la specificità era almeno il 95%. Inoltre, era chiaro che ChIP-seq offre sia a bassa complessità analitica e la sensibilità che aumenta con la profondità di sequenziamento.
Come tecnologie come, del genoma "nuova generazione" di sequenziamento forniscono 1-2 ordini di grandezza della quantità di sequenza che può essere costo-efficace generato più vecchie tecnologie 9. Metodi di ChIP-Seq quindi forniscono direttamente la copertura dell'intero genoma per un efficace profiling delle interazioni proteina-DNA di mammifero 3.
Nel 2006, una forte associazione di varianti del fattore di trascrizione 7-like 2 (TCF7L2) gene con diabete di tipo 2 è stato scoperto 10. Altri ricercatori hanno già replicato indipendentemente questo risultato in diverse etnie e, curiosamente, dai primi studi di associazione genome-wide di diabete di tipo 2 pubblicati su Nature 11,12 Scienza 13-15 e altrove 16,17, l'associazione più forte era effettivamente con TCF7L2, questo è ormai considerata la più significativa scoperta genetica nel diabete di tipo 2 a data 18-20. Inoltre, TCF7L2 è stato collegato al rischio di cancro 21,22, anzi, questa connessione è diventato più evidente quando il locus 8q24 rivelato da genoma ampi studi di associazione di un certo numero di tumori, tra carcinomi colorettali, ha dimostrato di essere dovuto ad un estremo a monte elemento TCF7L2 vincolante guida la trascrizione di MYC 23,24. Come tale, non vi è un grande interesse per la determinazione dei geni a valle regolati da questo fattore di trascrizione chiave.
Sulla base dell'esperienza con TCF7L2 come un esempio della metodologia, questo documento descrive come generare modello di DNA chip ad alta qualità. Chip è stato effettuato nella linea cellulare di carcinoma colorettale, HCT116, per la successiva sequenza per costruire un alto risolution mappa dei geni legati da TCF7L2 25 nel tentativo di dare una visione più completa per il suo ruolo chiave nella patogenesi di tratti complessi.
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. Cross-Link cromatina
- Crescere le cellule in piatti di coltura di cellule 100x20mm. La quantità di celle può variare da 1 a 10 milioni di cellule per piastra seconda del tipo cellulare. Circa 2 milioni di cellule è sufficiente per una immunoprecipitazione.
- Cellule del legame incrociato a 1% di formaldeide per 10 minuti a temperatura ambiente con dondolo occasionale.
- Quench reticolazione aggiungendo una concentrazione finale di 125 mM glicina e incubare per 5 min a temperatura ambiente.
- Lavare le cellule con fosfato 1X Soluzione salina tamponata (PBS) due volte, decantare PBS e aggiungere 0,2 ml di PBS.
- Celle di raccolta con un raschietto cellula di plastica in una provetta.
- Centrifugare le cellule a 2000 rpm per 5 minuti a 4 ° C.
- Aspirare il surnatante. Risospendere le cellule in SDS tampone di lisi (1% SDS, 10 mM EDTA, 50 mM Tris-HCl pH 8.1) per l'intero lisato o tenerli come pellet per l'estrazione nucleare.
- Le cellule possono essere salvati a -80 ° C oppure si può procedere immediately con sonicazione.
2. Preparare Nuclei (Andare al punto 3.5 per intero lisato)
- Supplemento Cell Lysis Buffer (5 mM PIPES pH 8.0, 85 mM KCl, 0.5% NP-40) con 1X proteinasi ogni esperimento.
- Risospendere scongelati pellet cellulare in circa 10 volte il volume di pellet con Cell Lysis Buffer.
- Dounce-omogeneizzare 10 volte con pestello poi incubare in ghiaccio per 10 min.
- Centrifugare campione a 4000 rpm per 5 minuti a 4 ° C, scartare il surnatante, e salvare pellet nucleare.
3. Sonicazione *
- Warm up SDS tampone di lisi e la quantità supplemento di tampone per essere utilizzato con proteinasi.
- Risospendere il pellet nucleare in SDS Lysis Buffer (circa 0,5 ml di tampone per 1-10.000.000 cellule)
- Incubare in ghiaccio per 10 min.
- Aggiungere aliquote da 0,5 ml di campioni per provette da microcentrifuga.
- Sonicare su ghiaccio bagnato utilizzando Misonix sonicator con 30 sec e 45 sec suoff in un ambiente ampiezza 2. Numero di cicli per dimensione ideale frammento può essere determinata prima provando varie numeri del ciclo (es. 2, 4, 8, 12, 16, e 20 o più cicli). Una diversa marca di sonicazione può essere utilizzato, tuttavia, le condizioni varieranno. La sperimentazione con il numero di cicli e la quantità di tempo e spegnimento devono essere eseguite per determinare le condizioni ideali.
- Raccogliere 20 ml di ogni campione per verificare i risultati sonicazione e di fare la quantificazione,. Il resto del campione può essere conservato a -80 ° C.
- Diluire il 20 l di campione con l'aggiunta di 30 ml di 0,1 X. tampone TE.
- Trattare campione con 1 ml di RNasi A a 37 ° C per 1 ora si aggiunge 1 ml di proteinasi K e incubare a 62 ° C per 2 h.
- Eseguire 20 microlitri del campione su un gel di agarosio al 2%.
- Purificare l'importo residuo del campione con il kit di purificazione PCR QIAquick poi quantificare con spettrofotometro NanoDrop.
* Per i nativi CHIP, microccocal nucleasi digestione può essere usato in alternativa al taglio del DNA.
4. Block Beads agarosio *
- Se perle sono già bloccati, procedere al punto 5.1.
- Utilizzare proteina A o proteina G agarosio. Per 5 immunoprecipitazione (IP), utilizzare 600 ml di 50% tallone liquami (300 ml tallone pellet)
- Per lavare le perline, centrifugare giù a 800 rpm per 1 min a 4 ° C e scartare il surnatante. Aggiungere un po 'più di 2 ml di ChIP diluizione (0,01% SDS, 1.2 mM EDTA, 167 mM NaCl, 1.1% Triton X-100, 16,7 mM Tris-HCl pH 8.1) e mescolare lentamente capovolgendo la provetta 10 volte. Spin giù di nuovo a 800 rpm per 1 min a 4 ° C e scartare il surnatante. Ripetere il lavaggio altre due volte.
- Bloccare perline ruotando a 4 ° C per una notte in una soluzione bloccante. Per la ricetta della soluzione di blocco, fare riferimento alla Tabella 1.
5. Pre-chiaro della cromatina
- Thaw sonicata cromatina sul ghiaccio.
- Centrifugare a 12.000 rpm fo 10 minuti a 4 ° C poi messo in ghiaccio immediatamente per rimuovere SDS (bianco pellet).
- Raccogliere il surnatante, scartare pellet, e combinare i campioni, se necessario.
- Estrarre gli importi necessari per l'esperimento sulla base di calcoli (1-10 ug della cromatina per IP).
- Diluire cromatina 10X in ChIP tampone di diluizione integrato con inibitore della proteasi.
- Aggiungere 100 ml di perline bloccate per IP.
- Ruota a 4 ° C per 1 ora.
6. Immunoprecipitation
- Centrifugare i campioni a 800 rpm per 1 min e trasferire il surnatante in una nuova provetta.
- Spin down surnatante a 800 rpm per 1 min e trasferimento in un'altra provetta pulita.
- Risparmiare 20 pl del supernatante, per servire come controllo di input, a -20 ° C.
- Aliquota della cromatina per il numero di indirizzi IP da fare nell'esperimento.
- Aggiungere 2 ug di anticorpo per 1-10 ug di cromatina per ogni campione.
- Incubare per una notte a 4 ° C con rotazione.
- Aggiungere 100 ml di perline bloccate per ogni campione IP.
- Incubare per 1 ora a 4 ° C con rotazione.
- Pellet le perline riducendo la velocità a 800 rpm per 1 min e scartare la maggior quantità di surnatante possibile.
- Lavare perle di una volta con sale tampone di lavaggio Complesso immunitario basso. Aggiungere 1 ml di tampone a ciascuna provetta; ruotare a temperatura ambiente per 5-8 min; centrifugare a 800 rpm per 1 minuto, quindi eliminare il surnatante. Ripetere il lavaggio una volta con Immune tampone di lavaggio ad alta Salt Complex e tampone di lavaggio complesso immune LiCl e due volte con tampone TE per un totale di 5 lavaggi (Tabella 2).
7. Eluizione
- Campioni di ingresso disgelo da giorno precedente per essere elaborati con i eluenti.
- Fai tampone di eluizione fresco (Tabella 3).
- Fare un master mix di abbastanza tampone di eluizione necessaria per IP e campioni di controllo di ingresso più 1-2 campioni extra.
- Aggiungere 100 microlitri di buffer di eluizione per ogni campione IP e incubare a temperatura ambiente per 15 mcon rotazione.
- Centrifugare a 800 rpm per 1 min e aggiungere surnatante in una nuova provetta.
- Aggiungere altri 100 ml di buffer di eluizione a ciascuna provetta di perline e incubare a temperatura della camera per 15 minuti con rotazione.
- Vortex per 15 secondi dopo l'incubazione, centrifugare a 5000 rpm per 1 minuto, quindi unire il surnatante con il surnatante dalla prima eluizione. (Assicurarsi che non vi siano rimasti più di perline nel surnatante. Se non sei sicuro, spin down surnatante di nuovo a 5.000 rpm per 1 minuto e raccogliere il surnatante in una nuova provetta.
- Aggiungere 180 ml di tampone di eluizione al 20 l di campioni di controllo di input.
8. Reverse Cross-Link
- Al 200 pl di eluenti e controlli di input, aggiungere 8 ml di NaCl 5 M.
- Tubi di sigillare con parafilm e incubare in bagnomaria a 65 ° C durante la notte.
9. Purificazione del DNA
- Trattare ogni campione con 1 ml di RNasi A per 1 ora a 37 ° C.
- Aggiungere 4 μl di 0,5 M EDTA, 8 microlitri 1M Tris-HCl, miscela, si aggiunge 1 ml di proteinasi K per ogni campione e incubare a 45 ° C per 2 h.
- Purificare i campioni utilizzando kit di purificazione PCR QIAquick. I campioni possono essere conservati a -20 ° C e controllo PCR può essere fatto in una data successiva.
* In alternativa, perle magnetiche ChIP-grado può essere usato al posto di agarosio per la porzione immunoprecipitazione.
10. Controllo PCR
- Per il controllo di PCR, utilizzare primer per regioni note per essere vincolati dalla proteina di interesse. Inoltre, utilizzare primer per le regioni non vincolanti come controlli negativi.
- Miscelare i reagenti per la reazione. Diluire il campione di ingresso a 1:100 (Tabella 3).
- Esegui reazione. Programma di PCR:
Passo 1: 94 ° C 3 min
Passo 2: 94 ° C 20 sec
59 ° C 30 sec
72 ° C 30 sec
(Ripetere il passaggio 2 per almeno 30 cycles)
Fase 3: 72 ° C 2 min
- Analizzare i campioni su 1% gel.
- L'arricchimento può anche essere determinato quantitativamente con real-time PCR.
Subscription Required. Please recommend JoVE to your librarian.
Representative Results
Una volta che la cromatina è stato sonicato e sono stati trattati con RNasi e proteinasi, i campioni eseguiti sul gel di agarosio 2% dovrebbero presentare uno striscio con il grosso del DNA alla dimensione voluta. Se più cicli differenti vengono testati, una graduale diminuzione della dimensione dovrebbe essere visto come il numero di cicli di aumento (Figura 2).
Dopo aver completato la porzione immunoprecipitazione del protocollo di arricchimento può sia essere controllato mediante PCR o PCR in tempo reale. Per i campioni di PCR eseguito su un gel di agarosio ci dovrebbe essere bande nel ingresso e il chip (utilizzando anticorpi per la proteina di interesse, che è TCF7L2 in questo caso) corsie di esempio e nulla o al massimo, una band molto debole (rumore di fondo) nel IgG (negativo) corsia di controllo per la regione di legame positivo. Per la regione di legame negativo non ci dovrebbe essere molto debole o nessuna banda per il controllo IgG e corsie chip. Ci dovrebbe essere una banda nella corsia di ingresso (Figura 3).
La figura 4 mostra gli stessi campioni esaminati mediante real-time PCR. Come con la precedente figura, ci dovrebbe essere un significativo arricchimento piega della regione di legame positivo per il campione ChIP sul controllo IgG. Inoltre, ci dovrebbe essere molto poco arricchimento, se presente, visto nella regione vincolante negativo.

Figura 1. Schema di flusso del processo di chip. Clicca qui per ingrandire la figura .
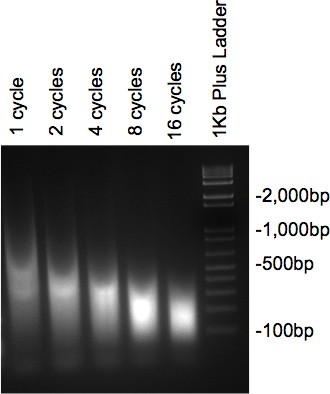
Figura 2. Gel controllare di sonicazione DNA.

Figura 3. PCR Controllare di chip.
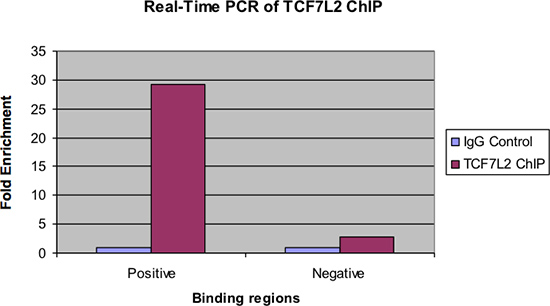
Figura 4. Real-time PCR di TCF7L2 chip.
| Reattivo | Volume |
| Perlina pellet | 300 microlitri |
| BSA (50 mg / ml) | 30 microlitri |
| 100X proteinasi | 10 microlitri |
| ChIP tampone di diluizione | 660 microlitri |
| Totale | 1.000 ml |
Tabella 1. Ricetta per il blocco di agarosio.
| Buffer | Componenti |
| Low Salt Immune Complex tampone di lavaggio | 0,1% SDS 1% Triton X-100 2 mM EDTA 20 mM Tris-HCl pH 8.1 150 mM NaCl |
| Alta Salt Immune Complex tampone di lavaggio | 0,1% SDS 1% Triton X-100 2 mM EDTA 20 mM Tris-HCl pH 8.1 500 mM di NaCl |
| LiCl Immune Complex tampone di lavaggio | 0,25 M LiCl 1% NP-40 1% Desossicolato 1 mM EDTA 10 mM Tris-HCl pH 8.1 |
| TE Buffer | 10 mM Tris-HCl pH 8.1 1 mM EDTA pH 8,0 |
Tabella 2. Tamponi di lavaggio chip.
| Reattivo | Volume |
| 10 microlitri | |
| 1 M NaHCO 3 | 20 microlitri |
| H 2 O | 170 microlitri |
Tabella 3. Tampone di eluizione di un IP.
| Reattivo | 50 microlitri di reazione | 20 microlitri di reazione |
| Acqua | 27 microlitri | 10,8 ml |
| Tampone di reazione PCR 5X | 10 microlitri | 4 pl |
| MgCl 2 | 4 pl | 1,6 microlitri |
| dNTP (10 mM) | 1 microlitri | 0,4 microlitri |
| Primer Mix (5 uM ciascuno) | 2 microlitri | 0,8 microlitri |
| Taq (Promega Hotstart) | 1 microlitri </ Td> | 0,4 microlitri |
| DNA ChIP | 5 microlitri | 2 microlitri |
Tabella 4. Volumi di reazione di PCR.
Subscription Required. Please recommend JoVE to your librarian.
Discussion
E 'ora possibile effettuare un genoma profilo di proteina-DNA associazione interazioni utilizzando ChIP-Seq, come è stato di recente dimostrato con altri fattori di trascrizione 2,3. La chiave per un esito sequenziamento di successo è la generazione di un modello di alta qualità cromatina immunoprecipitazione DNA.
Una volta che il DNA templato è stato generato e accertato essere opportunamente arricchito, si può poi prendere in preparazione per la successiva raccolta sequenziamento. Ad esempio, si può utilizzare il protocollo biblioteca sequenziamento fornito dal venditore, Illumina. La selezione del formato di questa libreria può essere eseguita mediante elettroforesi su gel e successiva escissione e purificazione del DNA nel ~ 200 - gamma di 700-bp. La riduzione delle dimensioni e restringendo la gamma di dimensioni di DNA raccolti da gel di purificazione è destinato a migliorare posizionale risoluzione di ChIP-Seq. Arricchendo per piccoli pezzi di DNA ingresso legati al fattore di interest, ci si aspetterebbe che la posizione del sito guadagnerà risoluzione. Selezione stretto dimensione migliora anche la dimensione uniformità di colonie molecolari prodotte sulla piattaforma Illumina. Tali dimensioni uniformità colonie aumenta anche il numero di lettura efficace ottenuta. Ingresso Shorter dimensione del DNA produce anche colonie più robuste sulla piattaforma Illumina, e questo può significare che i pezzi più brevi di DNA all'interno di una data distribuzione dei campioni di ingresso saranno rappresentati in modo più efficiente nella produzione sequenza finale che sono più lunghi pezzi di ingresso dalla stessa distribuzione.
Gli approcci bioinformatici per l'analisi della sequenza "di nuova generazione", sono in continua evoluzione, con molti fornitori che fanno il software open-source per un ulteriore affinamento. Si può trasformare la legge che mappa per posizioni genomiche unici in un frammento di DNA di sovrapposizione profilo. Picchi significativi possono essere identificati da profili threshholding a un'altezza equivalente ad un tasso stimato falsa scoperta. La posizione spmatrici di frequenza ecific derivati da questo lavoro possono essere utilizzati per identificare e localizzare i siti di legame del DNA in tutto il genoma umano per un dato fattore.
Ma bisogna essere cauti rispetto a quanto fattori uno desidera studiare con ChIP-Seq. Prima di intraprendere un tale studio si dovrebbe valutare se un anticorpo è disponibile sul mercato che è utilizzabile nel contesto di chip, come un povero anticorpo può avere effetti molto negativi sulla propri risultati sperimentali. Inoltre, si dovrebbe considerare se esistono isoforme di splicing della proteina studiata, anzi, TCF7L2 è noto per avere molti isoforme quindi siamo stati particolarmente cauti nella scelta di un anticorpo che si legavano ad aminoacidi costantemente presenti in tutti i principali isoforme di questo fattore di trascrizione 25.
In sintesi, la combinazione di cromatina immunoprecipitazione e sequenziamento ultra-alto-capacità (ChIP-seq) può identificare e mappare le interazioni proteina-DNA in un dato tessuto oclinea ell. Abbiamo delineato come generare un modello di circuito integrato di alta qualità per il successivo sequenziamento.
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
Gli autori dichiarano di non avere interessi finanziari in competizione.
Acknowledgments
Il lavoro è supportato da un Premio Istituto per lo sviluppo da Ospedale Pediatrico di Filadelfia.
Materials
| Name | Company | Catalog Number | Comments |
| QIAquick PCR Purification Kit | Qiagen | 28104 | |
| EZ-ChIP Kit | Millipore | 17-371 | |
| GoTaq Hot Start Polymerase | Promega | M5001 | |
| Misonix Sonicator | Qsonica | XL-2000 | |
| NanoDrop 1000 Spectrophotometer | Thermo-Scientific | ||
| Positive control primer sequences (TCF7L2-1) Forward- 5'-TCGCCCTGTCAATAATCTCC-3' Reverse- 5'-GCTCACCTCCTGTATCTTCG-3' Negative control primer sequences (CTRL-1) Forward-5'-ATGTGGTGTGGCTGTGATGGGAAC-3' Reverse- 5'-CGAGCAATCGGTAAATAGGTCTGG-3' |
|||
References
- Odom, D. T., et al. Control of pancreas and liver gene expression by HNF transcription factors. Science. 303, 1378-1381 (2004).
- Johnson, D. S., Mortazavi, A., Myers, R. M., Wold, B. Genome-wide mapping of in vivo protein-DNA interactions. Science. 316, 1497-1502 (2007).
- Robertson, G., et al. Genome-wide profiles of STAT1 DNA association using chromatin immunoprecipitation and massively parallel sequencing. Nature Methods. 4, 651-657 (2007).
- Reich, N. C., Liu, L.
- Lodige, I., et al. Nuclear export determines the cytokine sensitivity of STAT transcription factors. The Journal of Biological Chemistry. 280, 43087-43099 (2005).
- Schroder, K., Sweet, M. J., Hume, D. A. Signal integration between IFNgamma and TLR signalling pathways in macrophages. Immunobiology. 211, 511-524 (2006).
- Vinkemeier, U. Getting the message across, STAT! Design principles of a molecular signaling circuit. The Journal of Cell Biology. 167, 197-201 (2004).
- Brierley, M. M., Fish, E. N.
- Bentley, D. R.
- Grant, S. F., et al. Variant of transcription factor 7-like 2 (TCF7L2) gene confers risk of type 2 diabetes. Nature Genetics. 38, 320-323 (2006).
- Sladek, R., et al. A genome-wide association study identifies novel risk loci for type 2 diabetes. Nature. 445, 881-885 (2007).
- Wellcome Trust Case Control Consortium. Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature. 447, 661-678 (2007).
- Saxena, R., et al. Genome-wide association analysis identifies loci for type 2 diabetes and triglyceride levels. Science. 316, 1331-1336 (2007).
- Zeggini, E., et al. Replication of genome-wide association signals in UK samples reveals risk loci for type 2 diabetes. Science. 316, 1336-1341 (2007).
- Scott, L. J., et al. A genome-wide association study of type 2 diabetes in Finns detects multiple susceptibility variants. Science. 316, 1341-1345 (2007).
- Steinthorsdottir, V., et al. A variant in CDKAL1 influences insulin response and risk of type 2 diabetes. Nature Genetics. 39, 770-775 (2007).
- Salonen, J. T., et al. Type 2 Diabetes Whole-Genome Association Study in Four Populations: The DiaGen Consortium. American Journal of Human Genetics. 81, 338-345 (2007).
- Zeggini, E., McCarthy, M. I. TCF7L2: the biggest story in diabetes genetics since HLA. Diabetologia. 50, 1-4 (2007).
- Weedon, M. N.
- Hattersley, A. T. Prime suspect: the TCF7L2 gene and type 2 diabetes risk. The Journal of Clinical Investigation. 117, 2077-2079 (2007).
- Yochum, G. S., et al. Serial analysis of chromatin occupancy identifies beta-catenin target genes in colorectal carcinoma cells. Proceedings of the National Academy of Sciences of the United States of America. 104, 3324-3329 (2007).
- Duval, A., Busson-Leconiat, M., Berger, R., Hamelin, R. Assignment of the TCF-4 gene (TCF7L2) to human chromosome band 10q25.3. Cytogenet. Cell Genet. 88, 264-265 (2000).
- Pomerantz, M. M., et al. The 8q24 cancer risk variant rs6983267 shows long-range interaction with MYC in colorectal cancer. Nature Genetics. 41, 882-884 (2009).
- Tuupanen, S., et al. The common colorectal cancer predisposition SNP rs6983267 at chromosome 8q24 confers potential to enhanced Wnt signaling. Nature Genetics. 41, 885-890 (2009).
- Zhao, J., Schug, J., Li, M., Kaestner, K. H., Grant, S. F. Disease-associated loci are significantly over-represented among genes bound by transcription factor 7-like 2 (TCF7L2) in vivo. Diabetologia. 53, 2340-2346 (2010).
- Benjamini, Y., Yekutieli, D. Quantitative trait Loci analysis using the false discovery rate. Genetics. 171, 783-790 (2005).
