

Summary
De combinatie van chromatine immunoprecipitatie en ultra-high-throughput sequencing (ChIP-seq) kan identificeren en in kaart eiwit-DNA-interacties in een bepaald weefsel of cellijn. Geschetst is hoe je een hoge kwaliteit ChIP sjabloon voor de daaropvolgende sequencing, met ervaring met de transcriptiefactor TCF7L2 als een voorbeeld te genereren.
Abstract
ChIP-sequencing (ChIP-seq) methoden de rechtstreeks hele genoom dekking, waarbij een combinatie chromatine immunoprecipitatie (ChIP) en massaal parallel sequencing kan worden gebruikt om het repertoire van zoogdier-DNA-sequenties van transcriptiefactoren in vivo gebonden identificeren. "Next-generation" genoom sequencing technologieën bieden 1-2 ordes van grootte verhoging van het bedrag van de sequentie die kan worden kosteneffectief gegenereerd dan oudere technologieën waardoor voor ChIP-seq methoden om rechtstreeks te bieden het hele genoom dekking voor effectieve profilering van zoogdieren eiwit-DNA interacties.
Voor een succesvolle ChIP-seq benaderingen, moet men het genereren van hoge kwaliteit ChIP DNA-template om de beste sequencing resultaten te verkrijgen. De beschrijving is gebaseerd op ervaring met het eiwitproduct van het gen sterkst betrokken bij de pathogenese van type 2 diabetes, namelijk de transcriptiefactor transcriptiefactor 7-like 2 (TCF7L2). Deze factor is ook betrokken bij verschillende soorten kanker.
Geschetst is hoe hoge kwaliteit ChIP DNA template afgeleid van de colorectale carcinoma cellijn HCT116 genereren, om een hoge-resolutie-kaart bouwen door sequencing de genen van TCF7L2 gebonden bepalen nadere inzicht in de belangrijke rol in de pathogenese van complexe eigenschappen.
Introduction
Al vele jaren is er een onvervulde behoefte aan de set van genen verbonden en geregeld door een bepaald eiwit genomische, met name in de transcriptie factor klasse identificeren.
Odom et al.. 1 gebruikte chromatine immunoprecipitatie (ChIP) gecombineerd met promotor microarrays om de genen bezet door vooraf gespecificeerde transcriptieregulatoren in menselijke lever en alvleesklier eilandjes systematisch te identificeren. Vervolgens Johnson et al.. 2 ontwikkelde een grootschalige chromatine immunoprecipitatie assay gebaseerd op directe ultra high-throughput DNA-sequencing (ChIP-seq) om een uitvoerig in kaart eiwit-DNA-interacties over het hele zoogdieren genomen. Als een test case, zij toegewezen in vivo de binding van de neuron-restrictieve silencer factor (NRSF) tot 1946 locaties in het menselijk genoom. De weergegeven gegevens scherpe resolutie van binding positie (+ 50 basenparen), die zowel de i vergemakkelijktvertroosting van motieven en de identificatie van NRSF-bindende motieven. Deze ChIP-seq data had ook een hoge gevoeligheid en specificiteit en statistische betrouwbaarheid (P <10 -4), eigenschappen die belangrijk zijn voor het afleiden van nieuwe kandidaat-interacties zijn.
Robertson et al.. 3 ook ChIP-seq om STAT1 doelen in kaart interferon-γ (IFN-γ)-gestimuleerde en ongestimuleerde humane HeLa S3 cellen in vivo. Door ChIP-seq, met 15,1 en 12,9 miljoen unieke toegewezen sequentieaflezingen en schatting valse ontdekking van minder dan 0,001, identificeerden zij 41.582 en 11.004 vermoedelijke STAT1-bindende regionen gestimuleerde en ongestimuleerde cellen. Van de 34 loci bekend STAT1 interferon-responsieve bindingsplaatsen 4-8 bevatten, ChIP-seq gevonden 24 (71%). Werden ChIP-seq doelen verrijkt in sequenties vergelijkbaar met bekende STAT1 bindingsmotieven. Vergelijkingen met twee bestaande chip-PCR datasets voorgestelddat ChIP-seq sensitiviteit tussen 70% en 92% en specificiteit ten minste 95%. Bovendien, was het duidelijk dat ChIP-seq biedt zowel lage analytische complexiteit en gevoeligheid die toeneemt met sequencing diepte.
Als zodanig, "next-generation" genoom sequencing technologieën bieden 1-2 ordes van grootte verhoging van het bedrag van de sequentie die kosteneffectief gegenereerd dan oudere technologieën 9 kunnen zijn. ChIP-seq methoden dan ook direct leveren hele genoom dekking voor effectieve profilering van zoogdieren afkomstig eiwit-DNA-interacties 3.
In 2006, werd een sterke associatie van varianten in de transcriptiefactor 7-achtige 2 (TCF7L2) gen met type 2 diabetes ontdekt 10. Andere onderzoekers hebben reeds onafhankelijk gerepliceerd deze bevinding in verschillende etniciteiten en, interessant, vanaf de eerste genome wide association studies van type 2 diabetes gepubliceerd in Nature 11,12 Wetenschap 13-15 en elders 16,17, de sterkste associatie was inderdaad met TCF7L2; dit wordt nu beschouwd als de meest significante genetische bevinding bij type 2 diabetes tot nu 18-20. Bovendien is TCF7L2 verbonden met kankerrisico 21,22, ja, werd duidelijk dat dit verbreken als 8q24 locus onthuld door genoomwijde associatiestudies van verschillende kankers, waaronder colorectale carcinomen, werd aangetoond dat door een extreme upstream TCF7L2-bindend element besturen van de transcriptie van MYC 23,24. Als zodanig is er grote belangstelling voor het bepalen van de downstream genen gereguleerd door deze belangrijke transcriptiefactor.
Gebaseerd op ervaring met TCF7L2 als een voorbeeld van de methodologie, dit document wordt beschreven hoe u een hoge kwaliteit ChIP DNA-template te genereren. ChIP werd in het colorectaal carcinoom cellijn HCT116 uitgevoerd, voor daaropvolgende sequencing om het opbouwen van een hoge resolution kaart van de genen door TCF7L2 25 gebonden in een poging om meer inzicht te geven in haar belangrijke rol in de pathogenese van complexe eigenschappen.
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. Cross-Link Chromatin
- Groeien cellen in 100x20mm celcultuurschalen. De hoeveelheid cellen kan variëren van 1 tot 10 miljoen cellen per schaal afhankelijk van het celtype. Ongeveer 2 miljoen cellen is voldoende voor een immunoprecipitatie.
- Kruislings gekoppelde cellen in 1% formaldehyde gedurende 10 minuten bij kamertemperatuur met af en toe schudden.
- Quench verknoping door toevoeging van een uiteindelijke concentratie van 125 mM Glycine en incubeer gedurende 5 minuten bij kamertemperatuur.
- Was de cellen met 1X fosfaat gebufferde zoutoplossing (PBS) tweemaal decanteren PBS, en voeg dan 0,2 ml PBS.
- Oogst cellen met een plastic celschraper in een microcentrifugebuis.
- Spin down cellen bij 2000 rpm gedurende 5 min bij 4 ° C.
- Het supernatans aspireren. Resuspendeer cellen in SDS Lysisbuffer (1% SDS, 10 mM EDTA, 50 mM Tris-HCl pH 8,1) voor het gehele cellysaat of bewaar ze als een pellet voor nucleaire extractie.
- Cellen kunnen worden opgeslagen bij -80 ° C of men kan doorgaan immediately met ultrasoonapparaat.
2. Bereid Kernen (Ga naar stap 3.5 voor Whole Cell Lysate)
- Supplement Cell Lysis Buffer (5 mM PIPES pH 8,0, 85 mM KCl, 0,5% NP-40) met 1X Proteinase Inhibitor elk experiment.
- Resuspendeer celpellet ontdooid bij ongeveer 10 maal het volume pellet Cell Lysis Buffer.
- Dounce-homogeniseren 10 maal met stamper vervolgens incubeer op ijs gedurende 10 minuten.
- Centrifugeer steekproef bij 4.000 tpm gedurende 5 min bij 4 ° C, gooi supernatant, en bespaar nucleaire pellet.
3. Sonicatie *
- Opwarmen SDS Lysis Buffer en toeslag hoeveelheid buffer te gebruiken met Proteinase Inhibitor.
- Resuspendeer pellet in nucleaire SDS Lysis Buffer (ongeveer 0,5 ml buffer per 1-10.000.000 cellen)
- Incubeer op ijs gedurende 10 minuten.
- Voeg 0,5 ml porties van monsters microcentrifugebuizen.
- Ultrasone trillingen op nat ijs met behulp Misonix sonicator met 30 sec in en 45 secuit bij een amplitude instelling 2. Aantal cycli ideale fragment grootte kan worden bepaald door eerst proberen verschillende cyclus nummers (bijvoorbeeld 2, 4, 8, 12, 16 en 20 of meer cycli). Een ander merk sonicator worden gebruikt, echter de omstandigheden variëren. Experimenten met het aantal cycli en de tijd aan en uit worden uitgevoerd om de optimale omstandigheden te bepalen.
- Verzamel 20 pi van elk monster aan sonicatie resultaten te controleren en te kwantificeren doen,. De rest van het monster bij -80 ° C worden bewaard
- Verdun de 20 gl monster door toevoeging 30 pi 0,1 x TE-buffer.
- Behandel monster met 1 pl RNase A bij 37 ° C gedurende 1 uur voeg 1 pl proteïnase K en incubeer bij 62 ° C gedurende 2 uur.
- Run 20 ul van het monster op een 2% agarose gel.
- Zuiveren de resterende hoeveelheid monster met QIAquick PCR Purification kit vervolgens gekwantificeerd met behulp NanoDrop spectrofotometer.
* Voor inheemse ChIP kan microccocal nuclease digestie alternatief worden gebruikt om de DNA afschuiving.
4. Block agarosekralen *
- Als parels al zijn geblokkeerd, ga dan naar stap 5.1.
- Met Proteïne A of Proteïne G agarose. Voor 5 immunoprecipitaties (IP's), het gebruik 600 ul van 50% kraal slurry (300 pi kraal pellet)
- Om de parels te wassen, spin hen neer op 800 rpm gedurende 1 minuut bij 4 ° C. Verwijder supernatant. Voeg iets meer dan 2 ml ChIP Dilution Buffer (0,01% SDS, 1,2 mM EDTA, 167 mM NaCl, 1,1% Triton X-100, 16,7 mM Tris-HCl pH 8,1) en meng door langzaam het buisje 10X. Spin down opnieuw bij 800 rpm gedurende 1 minuut bij 4 ° C. Verwijder supernatant. Herhaal de wasbeurt nog 2 keer.
- Blokkeer korrels door het roteren bij 4 ° C geïncubeerd in blokkerende oplossing. Zie tabel 1 voor het recept van de blockingbuffer.
5. Pre-clear Chromatin
- Dooi gesoniceerd chromatine op ijs.
- Spin down bij 12.000 rpm fof 10 min bij 4 ° C zet dan op het ijs meteen aan SDS (witte pellet) te verwijderen.
- Verzamel supernatant, gooi pellet, en combineer monsters indien nodig.
- Nemen die nodig zijn voor het experiment op basis van berekeningen (1-10 ug van chromatine per IP) bedragen.
- Verdun chromatine 10X in ChIP Dilution Buffer aangevuld met proteinase inhibitor.
- Voeg 100 ul van geblokkeerde korrels per IP.
- Roteren bij 4 ° C gedurende 1 uur.
6. Immunoprecipitatie
- Spin down monsters bij 800 rpm gedurende 1 minuut en breng het supernatant naar een nieuwe buis.
- Spin down supernatant bij 800 rpm gedurende 1 minuut en overdracht naar een andere schone buis.
- Bewaar 20 ul van het supernatant, dat dient als ingang controle, bij -20 ° C.
- Aliquot chromatin het aantal IPs worden gedaan in het experiment.
- Voeg 2 ug antilichaam per 1-10 ug van chromatine aan elk monster.
- Incubeer overnacht 4 ° C onder rotatie.
- Voeg 100 ul van geblokkeerde kralen aan elk IP-monster.
- Incubeer gedurende 1 uur bij 4 ° C onder rotatie.
- Pellet de kralen door te stoppen met draaien bij 800 rpm gedurende 1 min en gooi zoveel van de bovenstaande mogelijk.
- Wassen kralen eenmaal met Low Salt Immuun Complex wasbuffer. Voeg 1 ml van buffer aan elke buis, roteren bij kamertemperatuur gedurende 5-8 min; gedeactiveerd bij 800 rpm gedurende 1 min, gooi supernatant. Herhaal eenmaal wassen met High Salt Immune Complex wasbuffer en LiCl Immune Complex wasbuffer en tweemaal met TE-buffer voor een totaal van 5 wasbehandelingen (Tabel 2).
7. Elutie
- Ontdooi ingangsmonsters van vorige dag worden verwerkt met de elutiemiddelen.
- Voeg Elution Buffer vers (tabel 3).
- Maak een master mix van voldoende Elutiebuffer nodig voor IP's en input controlemonsters plus 1-2 extra monsters.
- Voeg 100 ul elutiebuffer aan elk IP-monster en incubeer bij kamertemperatuur gedurende 15 mmet rotatie.
- Gedeactiveerd bij 800 rpm gedurende 1 min en voeg supernatant naar een nieuwe buis.
- Voeg nog eens 100 ul elutiebuffer aan elke buis kralen en incubeer bij kamertemperatuur gedurende 15 min met rotatie.
- Vortex gedurende 15 seconden na incubatie; gedeactiveerd bij 5000 rpm gedurende 1 min, vervolgens samen met de supernatant supernatant van de eerste elutie. (Zorg dat er geen overgebleven kralen in de bovenstaande vloeistoffen. Als je onzeker bent, spin down supernatans opnieuw bij 5000 rpm gedurende 1 minuut en verzamel de bovenstaande vloeistof in een nieuwe buis.
- Voeg 180 ul van Elutiebuffer aan de 20 ul van de input controlemonsters.
8. Reverse Cross-Link
- Om de 200 ul eluanten en input controles, voeg 8 pi van 5 M NaCl.
- Verbinding buizen met parafilm en incubeer in waterbad bij 65 ° C geïncubeerd.
9. DNA Purification
- Behandel elk monster met 1 pl RNase A gedurende 1 uur bij 37 ° C.
- Voeg 4 μl van 0,5 M EDTA, 8 pi 1 M Tris-HCl, mix, voeg 1 pl proteïnase K aan elk monster en incubeer bij 45 ° C gedurende 2 uur.
- Zuiveren de monsters met behulp van QIAquick PCR Purification kit. De monsters kunnen bij -20 ° C en PCR controle worden opgeslagen kan op een latere datum.
* Alternatief kan ChIP-grade magnetische korrels worden gebruikt in plaats van agarose voor immunoprecipitatie gedeelte.
10. PCR controle
- Voor de PCR controle primers gebruikt voor gebieden bekend het eiwit van belang gebonden. Gebruik ook primers voor niet-bindende gebieden als negatieve controles.
- Meng de reagentia voor de reactie. Verdun Input monster bij 1:100 (tabel 3).
- Run reactie. PCR programma:
Stap 1: 94 ° C 3 min
Stap 2: 94 ° C 20 sec
59 ° C 30 sec
72 ° C 30 sec
(Herhaal stap 2 voor ten minste 30 cycles)
Stap 3: 72 ° C 2 min
- Run monsters op 1% agarose gel.
- Verrijking kan ook kwantitatief worden bepaald met real-time PCR.
Subscription Required. Please recommend JoVE to your librarian.
Representative Results
Zodra het chromatine is gesonificeerd en behandeld met RNase en proteïnase bij de monsters lopen op 2% agarose gel uitstrijk vertonen met de massa van het DNA op de gewenste grootte. Indien meerdere cycli getest, een geleidelijke afname in grootte worden beschouwd als het aantal werkcycli verhogen (Figuur 2).
Na het voltooien van de immunoprecipitatie gedeelte van het protocol de verrijking ofwel kan worden gecontroleerd door middel van PCR of real-time PCR. Voor PCR monsters draaien op een agarosegel er bands in de Input-en chip (met behulp van antilichamen voor het eiwit van belang, dat is TCF7L2 in dit geval) monster rijstroken en niets of hooguit een zeer zwakke band (achtergrondgeluid) in het moet zijn IgG (negatieve) controle rijstrook voor de positieve binding regio. Voor het negatief bindend regio er moet zeer zwakke of geen band voor de IgG-controle en ChIP rijstroken. Er moet een band in de Input laan (figuur 3) zijn.
Figuur 4 toont dezelfde monsters onderzocht door real-time PCR. Zoals bij de vorige figuur, moet er een aanzienlijke voudige verrijking van de positieve bindingsgebied voor ChIP Sample via IgG controle. Ook moet er zeer weinig verrijking of geen gezien in de negatieve bindende regio.

Figuur 1. Stroomdiagram van ChIP proces. Klik hier om een grotere afbeelding te bekijken .
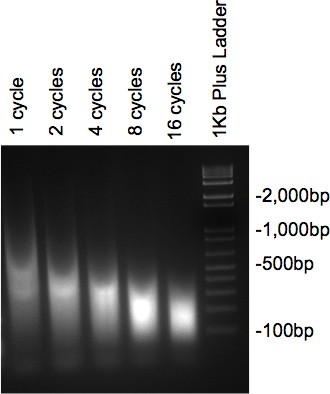
Figuur 2. Gel controleren van DNA ultrasoonapparaat.

Figuur 3. PCR controleren van de chip.
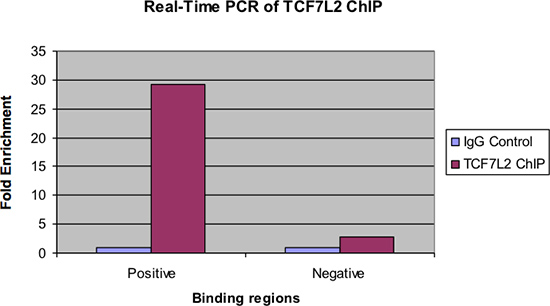
Figuur 4. Real-time PCR van TCF7L2 chip.
| Reagens | Volume |
| Kraal pellet | 300 gl |
| BSA (50 mg / ml) | 30 gl |
| 100X proteïnaseremmer | 10 gl |
| ChIP VerdunningsBuffer | 660 pl |
| Totaal | 1.000 III |
Tabel 1. Recept voor het blokkeren van agarose.
| Buffer | Onderdelen |
| Low Salt Immuun Complex Wash Buffer | 0.1% SDS 1% Triton X-100 2 mM EDTA 20 mM Tris-HCl pH 8,1 150 mM NaCl |
| High Salt Immuun Complex Wash Buffer | 0.1% SDS 1% Triton X-100 2 mM EDTA 20 mM Tris-HCl pH 8,1 500 mM NaCl |
| LiCl Immuun Complex Wasbuffer | 0,25 M LiCl 1% NP-40 1% deoxycholaat 1 mM EDTA 10 mM Tris-HCl pH 8,1 |
| TE-buffer | 10 mM Tris-HCl pH 8,1 1 mM EDTA pH 8,0 |
Tabel 2. ChIP wasbuffers.
| Reagens | Volume |
| 10 gl | |
| 1 M NaHCO3 | 20 gl |
| H2O | 170 pl |
Tabel 3. Elutiebuffer voor een IP.
| Reagens | 50 gl Reaction | 20 gl Reaction |
| Water | 27 pl | 10.8 pi |
| 5X PCR reactiebuffer | 10 gl | 4 ui |
| MgCl2 | 4 ui | 1.6 ul |
| dNTP (10 mM) | 1 ui | 0,4 pl |
| Primer mix (5 uM elk) | 2 pi | 0,8 pl |
| Taq (Promega Hotstart) | 1 ui </ Td> | 0,4 pl |
| ChIP DNA | 5 pi | 2 pi |
Tabel 4. PCR reactie volumes.
Subscription Required. Please recommend JoVE to your librarian.
Discussion
Het is nu mogelijk om een genoom-brede profiel van eiwit-DNA-interacties vereniging met ChIP-seq uit te voeren, zoals is zeer onlangs aangetoond met andere transcriptiefactoren 2,3. De sleutel tot een succesvolle sequencing resultaat is het genereren van een hoge kwaliteit chromatine immunoprecipitatie DNA template.
Zodra de DNA-template is gegenereerd en vastgesteld op adequate wijze worden verrijkt, kan men dan nemen het in voorbereiding bibliotheek voor daaropvolgende sequencing. Zo kan men de sequentie bibliotheek protocol door de verkoper, Illumina gebruikt. De grootte selectie van deze bibliotheek kan worden uitgevoerd door gelelektroforese en daaropvolgende excisie en zuivering van DNA in the ~ 200 - tot 700-bp range. Het verminderen van de omvang en het verkleinen van de orde van grootte van de DNA verzameld van gelzuivering is bedoeld om positionele resolutie van ChIP-seq verbeteren. Door verrijkend kleinere stukken inbreng DNA gebonden aan de factor interest, zou men verwachten dat de juiste locatie zal resolutie te krijgen. Strakker grootteselectie verbetert ook de grootte uniformiteit van moleculaire kolonies geproduceerd op de Illumina platform. Dergelijke koloniegrootte uniformiteit vergroot ook de effectieve lees-nummer verkregen. Kortere ingang DNA size produceert robuuster kolonies op de Illumina platform, en dit kan betekenen dat kortere DNA delen binnen elk ingangsmonster distributie efficiënter in de uiteindelijke volgorde uitgang vertegenwoordigd dan langer inbreng stukken van dezelfde verdeling.
De bioinformatic benaderingen van "next-generation" sequentie-analyse blijven evolueren, met veel leveranciers maken hun software open-source voor verdere verfijning. Men kan transformeren de leest die kaart om unieke genomische locaties in een DNA-fragment overlap profiel. Significante pieken worden geïdentificeerd door threshholding profielen op een hoogte overeenkomend met een geschatte false discovery rate. De positie specifieke frequentie matrices afgeleid uit dit werk kan worden gebruikt om DNA-bindingsplaatsen in de menselijke genoom voor een bepaalde factor te identificeren en te lokaliseren.
Maar men moet voorzichtig zijn met betrekking tot welke factoren men wil om te studeren met ChIP-seq. Worden Alvorens dergelijke studie moet men beoordelen of een antilichaam beschikbaar is op de markt die bruikbaar is in de ChIP omgeving als slecht antilichaam zeer schadelijk effect op iemands experimentele resultaten kan hebben. Bovendien moet men overwegen of er splice isovormen van het eiwit onder studie, inderdaad, TCF7L2 bekend dat vele isovormen dus we waren bijzonder voorzichtig selecteren van een antilichaam dat gebonden aminozuren consistent aanwezig in alle belangrijke isovormen van deze transcriptiefactor 25.
Samengevat kunnen de combinatie van chromatine immunoprecipitatie en ultra-high-throughput sequencing (ChIP-seq) eiwit-DNA-interacties in een bepaald weefsel of c identificeren en in kaartell lijn. We hebben geschetst hoe je een hoge kwaliteit ChIP sjabloon voor daaropvolgende sequencing genereren.
Subscription Required. Please recommend JoVE to your librarian.
Disclosures
De auteurs verklaren dat zij geen concurrerende financiële belangen hebben.
Acknowledgments
Het werk wordt ondersteund door een instituut Development Award van The Children's Hospital van Philadelphia.
Materials
| Name | Company | Catalog Number | Comments |
| QIAquick PCR Purification Kit | Qiagen | 28104 | |
| EZ-ChIP Kit | Millipore | 17-371 | |
| GoTaq Hot Start Polymerase | Promega | M5001 | |
| Misonix Sonicator | Qsonica | XL-2000 | |
| NanoDrop 1000 Spectrophotometer | Thermo-Scientific | ||
| Positive control primer sequences (TCF7L2-1) Forward- 5'-TCGCCCTGTCAATAATCTCC-3' Reverse- 5'-GCTCACCTCCTGTATCTTCG-3' Negative control primer sequences (CTRL-1) Forward-5'-ATGTGGTGTGGCTGTGATGGGAAC-3' Reverse- 5'-CGAGCAATCGGTAAATAGGTCTGG-3' |
|||
References
- Odom, D. T., et al. Control of pancreas and liver gene expression by HNF transcription factors. Science. 303, 1378-1381 (2004).
- Johnson, D. S., Mortazavi, A., Myers, R. M., Wold, B. Genome-wide mapping of in vivo protein-DNA interactions. Science. 316, 1497-1502 (2007).
- Robertson, G., et al. Genome-wide profiles of STAT1 DNA association using chromatin immunoprecipitation and massively parallel sequencing. Nature Methods. 4, 651-657 (2007).
- Reich, N. C., Liu, L.
- Lodige, I., et al. Nuclear export determines the cytokine sensitivity of STAT transcription factors. The Journal of Biological Chemistry. 280, 43087-43099 (2005).
- Schroder, K., Sweet, M. J., Hume, D. A. Signal integration between IFNgamma and TLR signalling pathways in macrophages. Immunobiology. 211, 511-524 (2006).
- Vinkemeier, U. Getting the message across, STAT! Design principles of a molecular signaling circuit. The Journal of Cell Biology. 167, 197-201 (2004).
- Brierley, M. M., Fish, E. N.
- Bentley, D. R.
- Grant, S. F., et al. Variant of transcription factor 7-like 2 (TCF7L2) gene confers risk of type 2 diabetes. Nature Genetics. 38, 320-323 (2006).
- Sladek, R., et al. A genome-wide association study identifies novel risk loci for type 2 diabetes. Nature. 445, 881-885 (2007).
- Wellcome Trust Case Control Consortium. Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature. 447, 661-678 (2007).
- Saxena, R., et al. Genome-wide association analysis identifies loci for type 2 diabetes and triglyceride levels. Science. 316, 1331-1336 (2007).
- Zeggini, E., et al. Replication of genome-wide association signals in UK samples reveals risk loci for type 2 diabetes. Science. 316, 1336-1341 (2007).
- Scott, L. J., et al. A genome-wide association study of type 2 diabetes in Finns detects multiple susceptibility variants. Science. 316, 1341-1345 (2007).
- Steinthorsdottir, V., et al. A variant in CDKAL1 influences insulin response and risk of type 2 diabetes. Nature Genetics. 39, 770-775 (2007).
- Salonen, J. T., et al. Type 2 Diabetes Whole-Genome Association Study in Four Populations: The DiaGen Consortium. American Journal of Human Genetics. 81, 338-345 (2007).
- Zeggini, E., McCarthy, M. I. TCF7L2: the biggest story in diabetes genetics since HLA. Diabetologia. 50, 1-4 (2007).
- Weedon, M. N.
- Hattersley, A. T. Prime suspect: the TCF7L2 gene and type 2 diabetes risk. The Journal of Clinical Investigation. 117, 2077-2079 (2007).
- Yochum, G. S., et al. Serial analysis of chromatin occupancy identifies beta-catenin target genes in colorectal carcinoma cells. Proceedings of the National Academy of Sciences of the United States of America. 104, 3324-3329 (2007).
- Duval, A., Busson-Leconiat, M., Berger, R., Hamelin, R. Assignment of the TCF-4 gene (TCF7L2) to human chromosome band 10q25.3. Cytogenet. Cell Genet. 88, 264-265 (2000).
- Pomerantz, M. M., et al. The 8q24 cancer risk variant rs6983267 shows long-range interaction with MYC in colorectal cancer. Nature Genetics. 41, 882-884 (2009).
- Tuupanen, S., et al. The common colorectal cancer predisposition SNP rs6983267 at chromosome 8q24 confers potential to enhanced Wnt signaling. Nature Genetics. 41, 885-890 (2009).
- Zhao, J., Schug, J., Li, M., Kaestner, K. H., Grant, S. F. Disease-associated loci are significantly over-represented among genes bound by transcription factor 7-like 2 (TCF7L2) in vivo. Diabetologia. 53, 2340-2346 (2010).
- Benjamini, Y., Yekutieli, D. Quantitative trait Loci analysis using the false discovery rate. Genetics. 171, 783-790 (2005).
