

Summary
РНК-секвенирования и биоинформатики анализы были использованы для определения существенно и дифференцированно выраженные факторы транскрипции в субпопуляции Lin-CD34 + и Лин-CD34- из EMLcells мыши. Эти факторы транскрипции может играть важную роль в определении переключатель между самообновляющихся Lin-CD34 + и частично дифференцированные Лин-CD34- клеток.
Abstract
Гемопоэтических стволовых клеток (ГСК) используются в клинике для лечения трансплантации для восстановления кроветворной системы пациента во многих заболеваний, таких как лейкоз и лимфома. Выяснение механизмов, контролирующих ГСК самообновление и дифференцировку важно для применения ГСК для исследований и клинического применения. Тем не менее, это не возможно, чтобы получить большое количество ГСК-за их неспособности к пролиферации в пробирке. Чтобы преодолеть это препятствие, мы использовали мозга получены линии клеток мыши кости, EML (эритроидных, миелоидный и лимфобластный) клеточной линии, в качестве модельной системы для данного исследования.
РНК-секвенирования (Секвенирование РНК) все чаще используется для замены микрочипов для исследований экспрессии генов. Мы сообщаем здесь подробный способ применения РНК-Seq технологию, чтобы исследовать потенциальные ключевые факторы в регуляции EML клеток к самообновлению и дифференцировке. Протокол предоставляется в данной работе, делится на три части. Первый номинальнаят объясняет, как культура EML клетки и отдельный Лин-CD34 + и Лин-CD34- клетки. Вторая часть протокола предлагает подробные процедуры для всего препарата РНК и последующего строительства библиотеки для высокой пропускной последовательности. Последняя часть описывает метод для анализа данных Секвенирование РНК и объясняет, как использовать полученные данные для выявления разному экспрессируются транскрипционные факторы между Лин-CD34 + и Лин-CD34- клеток. Наиболее существенно по-разному выраженные факторы транскрипции были определены как потенциальные ключевые регуляторы, контролирующие EML клеток к самообновлению и дифференцировке. В разделе обсуждения этого документа, мы выделяем ключевые шаги для успешного выполнения этого эксперимента.
Таким образом, этот документ предлагает способ использования РНК-Seq технологию для выявления потенциальных регуляторов самообновления и дифференцировки в EML клеток. Ключевыми факторами, выявленные подвергаются последующей функционального анализа в пробирке и Iн естественных условиях.
Introduction
Гемопоэтических стволовых клеток редкие клетки крови, которые находятся в основном в нише взрослого костного мозга. Они отвечают за производство клеток, необходимых для пополнения крови и иммунной систем 1. Как вид стволовых клеток, ГСК способны как самообновления и дифференцировки. Выяснение механизмов, которые контролируют решение судьбы ГСК, к любой самообновления или дифференциации, будет предлагать ценные указания на манипуляции ГСК для болезни крови исследований и клинического использования 2. Одна из проблем, с которой сталкиваются исследователи, что ГСК может поддерживаться и расширяться в пробирке в очень ограниченной степени; Подавляющее большинство их потомства частично дифференцированы в культуре 2.
В целях выявления ключевых регуляторов, которые управляют процессами самообновления и дифференцировки на генома масштабе, мы использовали мыши примитивный кроветворную линию клеток-предшественников EML в качестве модельной системы. Чтявляется клеточная линия была получена из мышиного костного мозга 3,4. Когда подается с различными факторами роста, EML клетки могут дифференцироваться в эритроидных, миелоидных и лимфоидных, клеток в пробирке 5. Важно отметить, что эта клеточная линия может распространяться в большом количестве в культуральную среду, содержащую фактор стволовых клеток (SCF) и до сих пор сохраняют свою мультипотентности. EML клетки могут быть разделены на субпопуляции самообновляющихся Лин-SCA + CD34 + и частично дифференцированы Лин-SCA-CD34- клеток, основанные на поверхностных маркеров CD34 и SCA 6. Подобно краткосрочного ГСК, SCA + CD34 + клеток способны к самообновлению. При обработке SCF, Лин-SCA + CD34 + клеток может быстро восстановить смешанную популяцию Лин-SCA + клеток CD34 + и Лин-SCA-CD34- и продолжают размножаться 6. Два популяции сходны по морфологии и имеют аналогичные уровни С-комплект мРНК и белка 6. Лин-SCA-CD34- клетки способны распространяющиеся в среде, содержащей IL-3, вместо SCF 3. Unveilinг ключевые регуляторы в клеточных судеб решения EML предложит лучшее понимание клеточных и молекулярных механизмов в начале переходного периода развития во кроветворения.
Для того чтобы исследовать основополагающие молекулярные различия между Самообновляющийся Лин-SCA + CD34 + и частично дифференцированных клеток Lin-SCA-CD34-, мы использовали Секвенирование РНК для идентификации разному экспрессируются гены. В частности, мы ориентируемся на транскрипционных факторов, как транскрипционные факторы имеют решающее значение в определении судьбы клеток. Секвенирование РНК является недавно разработанный подход, который использует возможности следующего поколения секвенирования (NGS) технологии для профилирования и количественно РНК транскрибируются с геном 7,8. Вкратце, тотальную РНК поли-выбран и фрагментарный как начальный шаблон template.The РНК затем превращают в кДНК с использованием обратной транскриптазы. Для отображения полнометражные РНК-транскриптов, используя нетронутыми, Неискаженный РНК для построения библиотеки кДНК важно. Для цепоза последовательности, специфические последовательности адаптера добавляются к обоим концам кДНК. Тогда, в большинстве случаев, молекулы кДНК амплифицировали с помощью ПЦР и секвенировали в высокой пропускной образом.
После секвенирования, то результат чтения может быть выровнен с опорным генома и базы данных транскриптома. Число считывает карту, что к опорному гена считается, и эта информация может быть использована для оценки уровня экспрессии гена. Читает также могут быть собраны заново без ссылки генома, что позволяет изучать transcriptomes в не-модельных организмов 9. Секвенирование РНК технология также используется для обнаружения сплайсинга изоформы 10-12 новых транскриптов генов 13 и 14 слияния. В дополнение к обнаружению белок-кодирующих генов, Секвенирование РНК также могут быть использованы для обнаружения нового и анализа уровня транскрипции некодирующих РНК, таких как длинные некодирующие РНК, микроРНК 15,16 17, 18 и т.д. миРНК. Из-за тон Точность этого метода, он был использован для детектирования единичных нуклеотидных вариаций 19,20.
До появления РНК-Seq технологии, микрочипов был основным методом для анализа профиля экспрессии генов. Предварительно предназначен зонды синтезировали и затем присоединены к твердой поверхности, чтобы сформировать микрочипов слайд 21. мРНК извлекают и превращают в кДНК. Во время обратного процесса транскрипции, флуоресцентно меченные нуклеотиды включены в кДНК и кДНК может быть гибридизации на микрочипе слайдов. Интенсивность сигнала, взятой в определенном месте, зависит от количества кДНК связывающего с зондом, специфичным на этом месте 21. По сравнению с РНК-Seq технологии, микрочипов имеет ряд ограничений. Во-первых, микрочипов опирается на уже существующей знания генной аннотации, в то время как Секвенирование РНК технология способна обнаруживать новые стенограммы при относительной высоком уровне фона, что ограничивает его применение когда GEпе уровень экспрессии является низким. Кроме того, Секвенирование РНК технология имеет много выше, динамический диапазон детектирования (8000 раз) 7, в то время как, из-за насыщения фона и сигналов, точность микрочипов ограничен для обоих весьма скромное и экспрессируемых генов 7,22. Наконец, микрочипов зонды отличаются их эффективности гибридизации, которые делают результаты менее надежны при сравнении относительных уровней экспрессии различных транскриптов в течение одного образца 23. Хотя Секвенирование РНК имеет много преимуществ по сравнению с микрочипом, ее анализ данных является сложным. Это одна из причин того, что многие исследователи все еще используют вместо микрочипов Секвенирование РНК. Различные инструменты биоинформатики необходимы для обработки и анализа 24 данных Секвенирование РНК.
Среди нескольких секвенирования следующего поколения (NGS) платформ, 454, Illumina, SOLID и Ion Torrent являются наиболее широко используемые из них. 454 была первой коммерческой платформы NGS. В отличие от других платформ секвенированиятаких как Illumina и SOLID, 454 платформы генерирует больше читать длина (в среднем 700 база читает) 25. Более читает лучше для начальной характеристике transcriptiome из-за их более высокой собрать эффективности 25. Основным недостатком в 454 платформе является его высокая стоимость Мегабазе последовательности. Illumina и SOLID платформы генерировать читает с увеличением числа и коротких длин. Стоимость одного Мегабазе последовательности значительно ниже, чем в 454 платформе. Из-за большого количества коротких читает для Illumina и твердых платформ, анализ данных намного более интенсивными вычислениями. Цена инструмента и реагентов для секвенирования на платформе Ion Torrent дешевле и время секвенирования короче 25. Тем не менее, частота ошибок и стоимость Мегабазе последовательности выше по сравнению с Illumina и твердых платформ. Различные платформы имеют свои преимущества и недостатки и требуют разных методов анализа данных. ПлаТГогт должны быть выбраны на основе цели секвенирования и наличия финансовых средств.
В этой статье, мы берем платформу Illumina Секвенирование РНК в качестве примера. Мы использовали EML клетку в качестве модельной системы для изучения ключевых регуляторов в EML клеток к самообновлению и дифференцировке, и при условии, подробные методы РНК-Seq строительства библиотеки и анализа данных для расчета уровня экспрессии и выявления новых транскриптов. Мы показали в нашей предыдущей публикации, что РНК-сл исследование в EML системы модели 2, в сочетании с функциональной пробы (например shRNA бросовой) обеспечить эффективный подход в понимании молекулярного механизма ранних стадиях кроветворной дифференциации, и может служить модель для анализа клеток к самообновлению и дифференцировке в целом.
Subscription Required. Please recommend JoVE to your librarian.
Protocol
1. EML Культура клеток и разделение клеток Lin-CD34 + и Лин-CD34- использованием магнитных сортировки клеток системы и флуоресценции активированных сортировка клеток Метод
- Подготовка хомячка почек (ВНК) среду для культивирования клеток для сбора стволовых клеток фактор:
- Культура ВНК клеток в DMEM среде, содержащей 10% FBS в 25 см 2 колбу (таблица 1) при 37 ° С, 5% СО 2 в инкубаторе для клеточных культур.
- Когда клетки вырастают до 80 - 90% слияния, мыть клетки один раз с 10 мл PBS. Добавляют 5 мл 0,25% раствора трипсина-ЭДТА в монослое и инкубировать клетки в течение 1-5 минут при комнатной температуре (RT), пока клетки не отделяются.
- Внесите решение вверх и вниз мягко, чтобы разбить комки клеток. Добавить 5 мл полной среды DMEM в колбу, чтобы остановить активности трипсина. Собирают клетки центрифугированием при 200 х г в течение 5 мин при комнатной температуре.
- Извлеките носитель и ресуспендируют осадок клеток в 10 мл клеточной культуральной среды свежей ВНК. Передача 2 мл клеточной суспензии со стадии 1.1.4 к новому 75 см 2 колбу и добавить 48 мл свежей ВНК клеточной культуральной среды в колбу.
- Культуры клеток ВНК в течение двух дней и собирать культуральной среды. Прохождение среда через 0,45 мкм фильтр. не следует хранить в среду -20 ° С до дальнейшего использования.
- EML культура клеток:
- Культура EML клетки (в виде суспензии) в СОЛ основной среде, содержащие ВНК клеток культуральной среды (таблица 1) при 37 ° С, 5% СО 2 в инкубаторе для клеточных культур.
- Поддержание клеток EML при низкой плотности клеток (0,5-5 × 10 5 клеток / мл) с пиковой плотностью менее 6 × 10 5 клеток / мл. Разделить клетки каждые 2-3 дня в соотношении 1: 5. Прохождение EML клетки мягко и отбросить культуру после пересева в течение 10 поколений.
- Истощение родословной положительных клеток:
- Урожай клетки EML центрифугированием при 200g FOR 5 мин и промыть клетки сразу с PBS. Собирают клетки центрифугированием при 200g в течение 5 мин.
- Ресуспендируют клеток с PBS и подсчет клеток с помощью гемоцитометра. Определить концентрацию антитела на последующей стадии разделени клеток в соответствии с количеством клеток (пожалуйста, смотрите инструкции, предлагаемых поставщика системы изоляции клеток).
- Изолировать клонов отрицательный (линейно) клетки с помощью коктейля родословная антитела (коктейль из биотин-сопряженных моноклональных антител CD5, CD45R (B220), CD11b, Anti-Gr-1 (Ли-6G / C), 7-4 и Тер-119 ) и магнитно активируется система сортировки клеток в соответствии с инструкциями изготовителя.
- Разделение клеток Lin-CD34 + и Лин-CD34-:
- Спин вниз по линейно клеток со стадии 1.3.3 при 200 х г в течение 5 мин. Ресуспендируйте осадок клеток с PBS и подсчитать клетки с гемоцитометре.
- Промывают клетки дважды FACS буфера и осаждения клеток при 200gв течение 5 мин.
- Этикетка пять 1,5 мл микроцентрифужных пробирок с номерами 1, 2, 3, 4, 5 соответственно. Ресуспендируют клеток с 100 мкл FACS буфера на 10 6 клеток (10 6 клеток на пробирку).
- Добавить 1 мкг анти-мышь CD34 FITC антитела к трубе 1 и трубки 2 и перемешать пробирки осторожно.
- Инкубируйте все пробирки при 4 ° С в течение 1 ч в темноте.
- Добавить 0,25 мкг РЕ-конъюгированных Anti-СЦА1 антитела и 20 мкл APC-сопряженных Lineage Коктейльные антитела к трубе 1, 0,25 мкг PE-сопряженных анти-СЦА1 антитела к трубке 3, и 20 мкл APC-сопряженных Lineage коктейль антител к Трубка 4.
- Смешать все пробирки осторожно и инкубировать клетки при 4 ° С в течение дополнительных 30 мин в темноте.
- Добавить 300 мкл FACS буфера к клеткам и спин вниз клетки при 200 х г в течение 5 мин.
- Промывают клетки с 500 мкл FACS буфера в течение трех раз.
- Ресуспендируют клеточный осадок в 500 мкл FACS буffer.
- Использование клеток в трубках 2, 3, 4, и 5 для настройки компенсации. Изолировать клетки Lin-SCA + CD34 + и Лин-SCA-CD34- в трубке 1, используя FACS Aria.
2. Получение РНК и библиотека Строительство для высокопроизводительного секвенирования
- Выделение, анализ качества и количественное определение РНК:
- Извлечение общей РНК из Лин-CD34 + и Лин-CD34- клеток соответственно с использованием TRIzol следующий производств »протокола.
- Снимите загрязненную ДНК с помощью ДНК-аза I (ДНКазы I) в соответствии с протоколом изготовления. По желанию, хранить РНК при -80 ° С на этом этапе для дальнейшего использования.
- Оценка качества тотальной РНК с использованием Bioanalyzer в соответствии с инструкциями, предлагаемых поставщика. Используйте образец РНК с РНК целостности номер (РИН) пива, чем 9.
- Библиотека Строительство и высокой пропускной последовательности:
ПРИМЕЧАНИЕ: Этот протокол описывает Секвенирование РНК с использованием платформы Illumina. Длядругие платформы секвенирования, различные библиотечные методы подготовки не требуется.- Используйте 0,1-4 мкг высококачественного общей РНК на образец для библиотеки подготовки. Обычно 2 мкг общей РНК можно экстрагировать из 10 5 клеток EML.
- Используйте систему подготовки пробы РНК-секвенирования для очистки РНК и фрагментации, первого и второго синтеза цепи кДНК, конец ремонта, 3 'концы аденилирование, адаптер перевязку и ПЦР-амплификации, следуя подробные стандартные процедуры из инструкции провайдера.
- Положительно выберите Поля мРНК с использованием олиго-DT магнитных шариков и фрагментировать мРНК.
- Выполнение обратную транскрипцию с использованием случайных праймеров для получения кДНК синтезируют, а затем второй цепи кДНК для генерирования двухцепочечной кДНК.
- Снять 3 'свесы и заполнить 5' свесы по ДНК-полимеразы. Аденилатциклазы 3 'концы, чтобы предотвратить фрагментов кДНК лигированием с друг с другом.
- Добавить мультиплекс индексации адаптеры для обоих концах dscDNA. Выполните ПЦР для обогащения фрагментов ДНК.
- Измерить A260 / A280, чтобы получить информацию о концентрации библиотеки с использованием спектрофотометра.
- Оценка качества библиотеки и измерить диапазон размеров фрагментов ДНК с использованием Bioanalyzer.
Анализ 3. Данные
Для справки программного обеспечения, используемого в этой части, см (таблица 2).
- Обработка файла данных для последующего анализа:
- Преобразование .bcl (файл вызова базовый) файл на .fastq файл, используя CASAVA программное обеспечение (Illumina, версия 1.8.2).
- Разожгите 'Терминал' в системе Linux. Перейдите в папку данных, содержащую файл данных из секвенирования машины Illumina HiSeq2000. Предположим, папка результат "NASboy1 / JiaqianLabData / HiSeq_RUN / 2013_07_11 / 130627_SN860_0309_A_2013-166_H0PW9ADXX / ', типав команде на рисунке S1A, и войти в папку данных.
- Установите CASAVA 1.8.2 в системе Linux. Предположим outputfolder является "Невыровненный ', используйте команду на рисунке S1B подготовить конфигурационный файл для преобразования. Используйте опцию --fastq-кластера подсчета 0 для обеспечения только один .fastq файл создается для каждого образца. Сформированный .fastq файл находится в .gz формате. Распакуйте его для последующего анализа (рис S1B).
- После "Невыровненный" папка была сформирована, пойти в "UNALIGNED" папки (рис S1C).
- Используйте команду на рисунке S1D, чтобы начать процесс преобразования. Параметр "-j" поставляет количество процессора, который будет использоваться.
- После того как система завершила процесс преобразования, перейдите в папку результата в разделе 'UNALIGNED "папки (рис S1E).
- Используйте команду на рисунке S1F </ Сильный> распаковать файл .fastq.gz в .fastq файла под каждой папке образца.
- Преобразование .bcl (файл вызова базовый) файл на .fastq файл, используя CASAVA программное обеспечение (Illumina, версия 1.8.2).
- Обнаружение новых транскриптов и оценить уровень экспрессии с помощью Tuxedo Люкс 26:
- Сопоставьте с двух концов Секвенирование РНК считывает с эталонной мыши генома (УСК версия MM9, полученной от http://cufflinks.cbcb.umd.edu/igenomes.html ) с помощью TopHat программное обеспечение (версия 1.3.3) 27, который использует Боути читать сопоставителя (версия 0.12.7) 28. Tophat поставляется с опцией "-нет-роман-juncs" для повышения точности оценки уровня экспрессии.
- Положите .fastq файлов в папке, где будет осуществляться процесс отображения. Предположим, есть 2 .fastq файлы (переименовать в Example1.read1, Example1.read2) для образца секвенирования с двух концов, используйте команду на рисунке S2 сделать отображение (отрегулировать параметры в соответствии с настройками системы).Параметр "-p" поставляет количество процессора, который будет использоваться. В "-r" и "-mate-STD-DEV" параметры могут быть получены из библиотеки QC или вывести из подмножества выровнены считывает (рис S2).
- Соберите переведённый читает в РНК-транскриптов с помощью программного обеспечения Запонки (версия 1.3.0) 29. Запуск Запонки с помощью файла аннотаций из известных генов (и тот же файл .gtf используется TopHat) и .bam файл, созданный TopHat.
- После Tophat завершения работы, в той же папке, используйте команду на рисунке S3A запустить запонки построить транскриптом и оценка транскриптов уровень экспрессии. "Mm9_repeatMasker.gtf" и файлы последовательности генома в папке 'GenomeSeqMM9' может быть получен из УСК Genome Browser.
- Полученные genes.expr и transcripts.expr файлы содержат значение экспрессии генов и транскриптов (изоформ). Копировать и вставлятьсодержимое файла в Excel файл и манипулировать с электронных таблиц (рис S3B).
- Используйте команду на рисунке S3C сравнить полученный 'transcripts.gtf "файл в" mm9_genes.gtf' файл эталонного с целью выявления новых транскриптов.
- В результате .tmap файл содержит результат сравнения. Скопируйте и вставьте содержимое файла в файл Excel и манипулировать с электронных таблиц. Стенограммы с классом кода 'и' можно рассматривать как «роман» по сравнению с базовыми .gtf предоставленного файла (рис S3D).
ПРИМЕЧАНИЕ: Для нижнего удобства анализа, установить значения FPKM до 0,1, если значения находятся под 0,1.
ПРИМЕЧАНИЕ: Шаг 3.2.3 - 3.2.6 не является обязательным для тех, кто желает повысить точность оценки экспрессии романистов транскриптов. Это займет гораздо больше времени, потому что отображение и транскриптомный строительство должны быть гООН не раз.
- Запустите Tophat использованием параметров по умолчанию, а затем запустить запонки в генерируемой .gtf файла с помощью команды в рисунке S3E.
- Сравните полученный .gtf файл к файлу .gtf ссылка генома с помощью команды в рисунке S3F.
- Разбор результате .tmap файл, как описано в шаге 3.2.2.4. Скопируйте и вставьте содержимое файла в файл Excel и манипулировать с электронных таблиц. Стенограммы с классом кода 'и' можно рассматривать как «роман» по сравнению с базовыми .gtf предоставленного файла.
- После стадии 3.2.5, существует файл .combined.gtf в папке, которую можно использовать в качестве опорного файла .gtf. Второй пробег TopHat и запонки могут быть выполнены, как описано в шаге 3.2.1 и 3.2.2, чтобы получить более точную оценку FPKM о новых транскриптов.
- Сопоставьте с двух концов Секвенирование РНК считывает с эталонной мыши генома (УСК версия MM9, полученной от http://cufflinks.cbcb.umd.edu/igenomes.html ) с помощью TopHat программное обеспечение (версия 1.3.3) 27, который использует Боути читать сопоставителя (версия 0.12.7) 28. Tophat поставляется с опцией "-нет-роман-juncs" для повышения точности оценки уровня экспрессии.
- Обнаружение differentiallу выразил генов с помощью DESeq пакет 30.
- Ввод DESeq является сырым стол на счету чтения. Чтобы получить такую таблицу, используйте сценарий htseq-счета распределенную с пакетом HTSeq Python, которые можно загрузить с веб-сайта HTSeq ( http://www-huber.embl.de/users/anders/HTSeq/doc/count.html ) ,
- Убедитесь, что samtools, питон, и htseq-счетчик programsare установлен в системе. Получить исходные цифры подсчета чтения из производства TopHat с помощью команды в рисунке S4A.
- Подготовить «Raw_Count_Table.txt ', файлы" ExperimentDesign.txt', используя Excel. Скопируйте и сохранить содержимое в формате .txt для DESeq R пакета (рис S4B).
- Установите R программу в системе. В терминале, тип "R" и нажмите ENTER.A экран сообщение будет appearas показали на рисунке S4C.
- Читайте «Raw_Count_Table.txt ',' ExperimentDesign.txt 'в R с помощью команды в рисунке S4D.
- Загрузите DESeq пакет с помощью команды в рисунке S4E.
- Факторизовать условия в R (рис S4F).
- Используйте команду на рисунке S4G запустить негативную двухмандатной тест на нормированной таблицы подсчета.
- Используйте команду на рисунке S4H для вывода значительной дифференциальных выраженных генов в файле .csv.
- Ввод DESeq является сырым стол на счету чтения. Чтобы получить такую таблицу, используйте сценарий htseq-счета распределенную с пакетом HTSeq Python, которые можно загрузить с веб-сайта HTSeq ( http://www-huber.embl.de/users/anders/HTSeq/doc/count.html ) ,
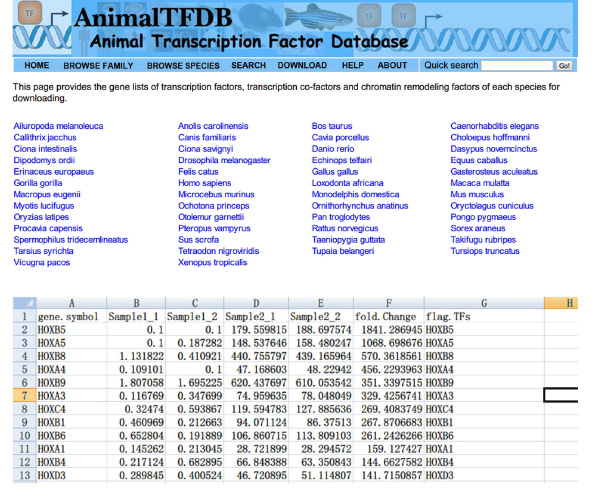
- Транскрипционные факторы Поиск "(TFS) значения FPKM через образцов с использованием Excel. Пересечь DE стол ген и ТФ стол. Гены принадлежат как таблицы дифференциально экспрессируются транскрипционные факторы.
- Перейти на сайт http://www.bioguo.org/AnimalTFDB/download.php и скачать транскрипционные факторы. Тогда выполните поиск транскрипционные факторы DE в Excel (< сильный> Рисунок S5).
- Создание .bigwig файл для визуализации геном браузера УСК.
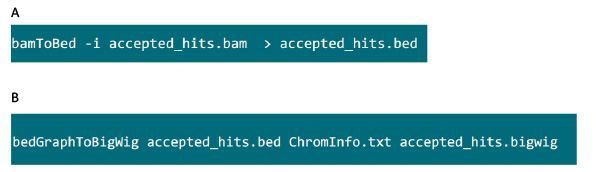
- Скачать пакет программного обеспечения "bedtools" с сайта https://github.com/arq5x/bedtools2 и установить программное обеспечение в системе 31. Скачать инструменты УСК "bedGraphToBigWig" с сайта http://hgdownload.cse.ucsc.edu/admin/exe/ и установить программное обеспечение в системе.
- В папке, содержащей файл .bam, используйте команду на рисунке S6A конвертировать .bam файл, сгенерированный TopHat в .bed файла.
- После .bed файл производится с помощью команды в рисунке S6B генерировать .bigwig файл. Файл "ChromInfo.txt 'может быть получен из следующему адресу:Arget = "_blank"> http://hgdownload.cse.ucsc.edu/goldenPath/mm9/database/chromInfo.txt.gz.
- Соблюдайте пользовательский трек на УСК Genome Browser. Обратитесь к веб-сайте http://genome.ucsc.edu/goldenPath/help/customTrack.html о том, как отобразить пользовательский трек, используя УСК генома браузер.

Рисунок S1: Преобразование .bcl файл .fastq файл, используя CASAVA программного обеспечения.

Рисунок S2: Mapping читает ссылаться геном с помощью TopHat.
Рисунок S3: Обнаружение новых транскриптов и оценки уровня экспрессии.

Рисунок S4: Вызов дифференциального выраженную ген с помощью DESeq пакет.

Рисунок S5: Идентификация дифференциально выраженных факторов транскрипции.

Рисунок S6: Преобразование результат отображения для визуализации данных.
Subscription Required. Please recommend JoVE to your librarian.
Representative Results
Для того чтобы проанализировать разному экспрессируются гены в Лин-CD34 + и Лин-CD34- EML клеток, мы использовали РНК-Seq технологии. Рисунок 1 показывает рабочий процесс процедур. После выделения клона негативных клеток магнитным сортировки клеток, мы расстались Лин-SCA + CD34 + и Лин-SCA-CD34- клеток с использованием FACS Aria. Лин-обогащенные клетки EML окрашивали анти-CD34, анти-СЦА1 и рода коктейль антител. Только линейно клетки закрытого для анализа СЦА1 и CD34 выражения. Две популяции (SCA + CD34 + и SCA-CD34- EML клетки) можно было наблюдать с помощью анализа FACS (рисунок 2) 6.
После отделения клеток, мы экстрагировали тотальную РНК из CD34 + и CD34- клеток соответственно и анализировали качество РНК. Точность РНК-Seq данных в значительной степени зависит от качества РНК-Seq библиотеки и качество тотальной РНК является жизненно важным для получения библиотеки высокого качества. Высокое качество образца РНК должны иметь OD 260/280 значение от 1.8 и 2,0. В дополнение к помощи спектрофотометра, качество РНК дополнительно оценивали с большей точностью по Bioanalyzer. 3 показан результат высокого качества РНК образца с RIN, равной 9,4. Только высокое качество тотальную РНК образец со значением больше, чем RIN 9 использовали для экстракции мРНК и последующих библиотеки процедур строительства.
Рибосомальной РНК является наиболее распространенным типом РНК в клетке. В настоящее время две основные стратегии, истощение рРНК или положительно выбор полиаденилированных мРНК (поли-мРНК), используются для обогащения РНК-мишени до создания библиотеки. Номера полиаденилированных видов РНК теряются при выборе поли-A мРНК. В отличие от этого, рРНК методы, такие как истощение RiboMinus может сохранить удобства Полиаденилированная видов РНК. Цель нашего исследования состоит в поиске разному экспрессируются гены, кодирующие в двух типах клеток, таким образом, мы использовали поли-метода отбора мРНК для обогащения целевых РНК до библиотеки строителие. Когда библиотека строительство было закончено, размер фрагментов ДНК в библиотеке было проверено до секвенирования с использованием Bioanalyzer. Рисунок 4 показывает хорошую библиотеку качества с размером фрагмента пиков в около 300 пар.
В последующей стадии, библиотека была подвергнута высокой пропускной последовательности. В принципе, больше читать длина будет полезно для картирования чтений. Это может уменьшить вероятность того, что для чтения отображается в нескольких местах из-за сходства между дублированных генов или членов семейства генов. Как последовательности секвенирования пара-концевые являются от обоих концов фрагментов, длина чтения выбраны должна быть не менее половины средней длины фрагментов. Если главная цель эксперимента является измерение уровня экспрессии вместо построения структуры транскриптов, один конец читать (75 или 100 б.п.) может снизить стоимость, не теряя слишком много информации. Парные конец последовательности является более полезным для строительства структуры стенограмма и корочечитать длину может быть использован, чтобы уменьшить стоимость. Конечно, когда достаточное финансирование доступно, предпочтительнее больше читать длина.
Для дифференциального анализа экспрессии, существует много альтернативных алгоритмы, отличные от DESeq. Существует также одна включены в запонки пакета с именем cuffdiff 32. DESeq является одним из алгоритмов анализа генов DE наиболее широко используемым количества основаны. Метод DESeq основан на хорошо охарактеризованного статистики модели - отрицательного биномиального распределения. По нашему опыту, DESeq является более стабильным по сравнению с cuffdiff. Ранние версии cuffdiff часто дают значительно различное число DE генов. Поэтому мы использовали DESeq для анализа DE здесь.
Потому что транскрипционные факторы имеют решающее значение для определения судьбы клеток, мы сосредоточены на значительно дифференциально выраженной факторов транскрипции 33. ТФ изменилось> 1,5 раза между Лин-CD34 + и Лин-CD34- были найдены и показаны на Тепловая карта (Figurе 5) 2. Следует отметить, что относительный уровень экспрессии Tcf7 в Lin-CD34 + клеток более, чем в 100 раз выше, чем в Лин-CD34- клеток. Таким образом Tcf7 был выбран для дальнейшего чип-секвенирования (иммунопреципитации хроматина и секвенирования) анализа и функционального тестирования для подтверждения функции Tcf7 'ы в регуляции EML клеток к самообновлению и дифференцировке 2.

Фигура 1:. Рабочий процесс процедур Lin-CD34 + и CD34- Лин-клетки были отделены от магнитной системы сепарации клеток и метода сортировки флуоресценции активированных клеток. Суммарную РНК экстрагировали с последующей очисткой мРНК и создания библиотеки. После анализа качества библиотеки, образцы были подвергнуты высокой пропускной последовательности. Данные были проанализированы и дифференциально экспрессируются факторы транскрипции были определены.

Рисунок 2: Разделение Лин-CD34 + и Лин-CD34- EML клеток 6 клеток линейно EML обогатились магнитного сортировки клеток.. Линейно клетки окрашивали анти-CD34, анти-СЦА1 и линия смеси антител. Линейно клетки закрытого для выражения CD34 и СЦА1. Лин-CD34 + SCA + и популяции Lin-CD34-скалярных EML клеток были отсортированы.

На рисунке 3:. Представитель высококачественного образца тотальной РНК Качество тотальной РНК оценивали с помощью Bioanalyzer. РНК целостности Количество 9,4 (FU, флуоресценции Units).

Рисунок 4:. Фрагменты диапазон размер парного библиотеке ДНК размер дистрибутива библиотеки были проанализированы с использованием Bioanalyzer. Большинство фрагменты находятся в диапазоне размеров 250-500 п.н..

Для каждого типа клеток, были выполнены разному экспрессируются факторы транскрипции (> 1,5 раза) между Лин-CD34 + клеток и Лин-CD34- клеток 2 два независимых эксперимента: Рисунок 5.. UP-регулируемых генов, обозначены как красный цвет и вниз-регулируемых генов, обозначены как зеленый цвет.
Таблица 1: Буферы и клеточной среды для культивирования.
| Программное обеспечение | Использование | Ссылка | |||
| Галстук-бабочка 1.2.7 | Используется TopHat для отображения | [28] | |||
| Tophat 1.3.3 | Отображение читает обратно референсный геном | [27] | |||
| Запонки 1.3.0 | Строительство Стенограммы и оценка уровня экспрессии | [29] | |||
| DESeq 1.16.0 | Дифференциальный анализ экспрессии | [30] | Bedtools 2.18 | Преобразование .bam файл в .bed файла | [31] |
| bedGraphToBigWig | Преобразование .bed файл .bigwig файл | http://genome.ucsc.edu/ |
Таблица 2: Список программного обеспечения для анализа данных.
Subscription Required. Please recommend JoVE to your librarian.
Discussion
Млекопитающих транскриптомный является очень сложным 34-38. Секвенирование РНК технология играет все более важную роль в исследованиях анализа транскриптома, выявления новых транскриптов и открытия вариации одного нуклеотида и т.д. Она имеет много преимуществ по сравнению с другими методами для анализа экспрессии генов. Как уже упоминалось во введении, это преодолевает гибридизации артефакты микрочипов и могут быть использованы для идентификации новых транскриптов De Novo. Одним из ограничений РНК-секвенирования является относительная длина короткого чтения по сравнению с Sanger секвенирования. Тем не менее, с быстрым улучшением технологии последовательности, читать Длина постоянно растет. В этой статье, мы предоставляем подробные методы с использованием этой технологии, чтобы выявить потенциальные регуляторы ключевых в мыши EML клеток к самообновлению и дифференцировке.
Первый ключевой шаг для этого протокола является EML культуры клеток. Хотя ПОЛС является гемопоэтических клеточной линией предшественников и это может бытьразмножают в большом количестве с SCF. Культивирование состояние EML клеток требуется больше внимания, чем обычные иммортализованных клеточных линий. Клетки должны быть поданы и пассировать на регулярной основе с нежным работы; в противном случае клетки может измениться в их свойствах самообновления и дифференцировки и подвергаются клеточной гибели. В качестве первого шага после сбора достаточного количества клеток, мы выделили клональные негативные клетки, используя магнитную систему сортировки активирована клеток. Тогда мы отделены CD34 + и CD34- клеток с помощью флуоресцентной активированный сортировки клеток. Клетки EML, как правило, пассировать менее 10 поколений, прежде чем использовать для экстракции РНК и числа CD34 + и CD34- клеток должна быть похожа после разделения. Если две популяции сильно различаются по числу клеток, желательно, чтобы отбросить культуру и повторно оттаивать другой трубки клеточной культуры складе.
После отделения CD34 + и CD34- клетки, общая добыча РНК выполняли, еще один важный шаг для этого улУды. Высокое качество РНК является основой для построения библиотеки высокого качества, которая обещает точность данных секвенирования. В этой критической стадии, любой контакт с РНКазой следует избегать. Все реагенты должны быть РНКазы. Важно носить перчатки в любое время при работе РНК. Высокое качество образца РНК имеет 260/280 значение ОП между 1,8 и 2,0. При сборе водной фазы, содержащей РНК, будьте осторожны, не несут никакой органической фазы образца РНК. Любые остаточные органические растворители, такие как фенол или хлороформ в РНК приведет к OD260 / 280 значением ниже, чем 1,65. Если / 280 значение OD260 ниже, чем 1,65, выпадают в осадок РНК снова этанолом. После промывки 75% -ным этанолом, не пересушить РНК гранул. Сушка осадок РНК полностью повлияет на растворимость РНК и привести к низкой урожайности РНК.
Следующий ключевой шаг для этого протокола является библиотека подготовка. После полного выделения РНК, шагом с помощью ДНКазы для удаления загрязненной ДНК яS рекомендуется, так как загрязнение ДНК может привести к неправильной оценки количества общей РНК, используемой. Рекомендуется, чтобы немедленно выполнить процедуру ниже по потоку после выделения РНК, так как после длительного хранения и замораживания-оттаивания процедуру, РНК будет деградировать в некоторой степени. Если последующие стадии после выделения РНК не может быть выполнено немедленно, хранить в РНК -80 ° С. Перед тотальную РНК используется для очистки мРНК и синтез кДНК, качество всегда должно быть проверено. Только высокое качество РНК могут быть использованы для библиотеки подготовки. Использование низкого качества или деградированных РНК может привести к чрезмерной представление 3 'концы. Перед секвенирования, библиотека Оценку качества для обеспечения максимальной эффективности секвенирования.
В анализе данных части, после выполнения пробег Запонки без ссылки транскриптома, мы объединили новые стенограммы с известными транскриптов, чтобы сформировать ссылку .gtf файл и запустите TopHat и запонки во второй раз.Эта процедура два перспективе рекомендуется, так как это обеспечивает более точную оценку FPKM чем работает только один раз. После анализа данных, были выявлены дифференциально выраженные гены. Downstream эксперименты могут быть выполнены, чтобы проверить функции генов в пробирке и в естественных условиях. В нашей предыдущей публикации 2, мы выбрали значительно разному экспрессируются транскрипционные факторы и определили геном сайт связывания этих факторов, выполняя хроматина иммунопреципитацию и последовательности (чип-Seq). Кроме того, мы применили shRNA нокдаун анализа, чтобы проверить функциональное влияние Tcf7. Мы обнаружили, что в Tcf7 нокдаун клеток, повышающей регуляции генов были гены сильно обогащены CD34- клеток, в то время как понижающей регуляции генов было обнаружено, значительно обогащенный CD34 + клеток. Таким образом, профиль экспрессии генов Tcf7 бросовым клеток смещается в сторону частично дифференцированного CD34- state.Overall, используя EML клетку в качестве модельной системыв сочетании с РНК-секвенирования технологии и функциональных анализов, мы определили и подтвердили Tcf7 как важный регулятор EML клеток к самообновлению и дифференцировке.
Subscription Required. Please recommend JoVE to your librarian.
Materials
| Name | Company | Catalog Number | Comments |
| Antibiotic-Antimycotic | Invitrogen | 15240-062 | BHK cell culture |
| Anti-Mouse CD34 FITC | eBioscience | 11-0341-81 | FACS sorting |
| Anti-Mouse Ly-6A/E (Sca-1) PE | eBioscience | 12-5981-81 | FACS sorting |
| APC Mouse Lineage Antibody Cocktail | BD Biosciences | 558074 | FACS sorting |
| BD FACSAria Cell Sorter | BD Biosciences | Special offer sysmtem | FACS sorting |
| Corning™ Cell Culture Treated Flasks 75 cm2 | Corning incorporated | 430641 | Cell culture |
| Corning™ Cell Culture Treated Flasks 25 cm2 | Corning incorporated | 430639 | Cell culture |
| Deoxyribonuclease I, Amplification Grade | Invitrogen | 18068-015 | Library preparation |
| DMEM | Invitrogen | 11965-092 | BHK cell culture |
| DPBS | Gibco | 14190 | Cell culture |
| HI FBS | Invitrogen | 16140071 | BHK cell culture |
| Horse Serum | Invitrogen | 16050-122 | EML cell culture |
| IMDM | HyClone | SH30228.02 | EML cell culture |
| L-Glutamine | Invitrogen | 25030-081 | Cell culture |
| Lineage Cell Depletion Kit, mouse | Miltenyi Biotec | 130-090-858 | Isolation of lineage negative cells |
| NanoVue Plus spectrophotometer | GE Healthcare | 28-9569-62 | Quality control |
| Thermo Scientific™ Napco™ 8000 Water-Jacketed CO2 Incubators | Thermo Scientific | 15-497-002 | Cell culture |
| Penicillin-Streptomycin | Invitrogen | 15140-122 | EML cell culture |
| TRIzol® Reagent | Invitrogen | 15596-018 | RNA exraction |
| TruSeq™ RNA Sample Prep Kit v2 -Set B (48 rxn) | Illumina | RS-122-2002 | Library preparation |
| 2100 Electrophoresis Bioanalyzer Instrument | Agilent | G2939AA | Quality control |
| 0.25% Trypsin-EDTA | Gibco | 25200 | Cell culture |
| 0.45 µm Syringe Filters | Nalgene | 190-2545 | Cell culture |
References
- Chambers, S. M., Goodell, M. A. Hematopoietic stem cell aging: wrinkles in stem cell potential. Stem Cell Rev. 3, 201-211 (2007).
- Wu, J. Q., et al. Tcf7 is an important regulator of the switch of self-renewal and differentiation in a multipotential hematopoietic cell line. PLoS genetics. 8, (2012).
- Ye, Z. J., et al. Complex interactions in EML cell stimulation by stem cell factor and IL-3. Proceedings of the National Academy of Sciences of the United States of America. 108, 4882-4887 (2011).
- Tsai, S., Bartelmez, S., Sitnicka, E., Collins, S. Lymphohematopoietic progenitors immortalized by a retroviral vector harboring a dominant-negative retinoic acid receptor can recapitulate lymphoid, myeloid, and erythroid development. Genes Dev. 8, 2831-2841 (1994).
- Weiler, S. R., et al. D3: a gene induced during myeloid cell differentiation of Linlo c-Kit+ Sca-1(+) progenitor cells. Blood. 93, 527-536 (1999).
- Ye, Z. J., Kluger, Y., Lian, Z., Weissman, S. M. Two types of precursor cells in a multipotential hematopoietic cell line. Proc Natl Acad Sci U S A. 102, 18461-18466 (2005).
- Wang, Z., Gerstein, M., Snyder, M. RNA-Seq: a revolutionary tool for transcriptomics. Nature reviews. Genetics. 10, 57-63 (2009).
- Chu, Y., Corey, D. R. RNA sequencing: platform selection, experimental design, and data interpretation. Nucleic acid therapeutics. 22, 271-274 (2012).
- Hornett, E. A., Wheat, C. W. Quantitative RNA-Seq analysis in non-model species: assessing transcriptome assemblies as a scaffold and the utility of evolutionary divergent genomic reference species. BMC genomics. 13, 361 (2012).
- Eswaran, J., et al. RNA sequencing of cancer reveals novel splicing alterations. Scientific reports. 3, 1689 (2013).
- Wang, E. T., et al. Alternative isoform regulation in human tissue transcriptomes. Nature. 456, 470-476 (2008).
- Wu, J. Q., et al. Dynamic transcriptomes during neural differentiation of human embryonic stem cells revealed by short, long, and paired-end sequencing. Proceedings of the National Academy of Sciences of the United States of America. 107, 5254-5259 (2010).
- Loraine, A. E., McCormick, S., Estrada, A., Patel, K., Qin, P. RNA-seq of Arabidopsis pollen uncovers novel transcription and alternative splicing. Plant physiology. 162, 1092-1109 (2013).
- Edgren, H., et al. Identification of fusion genes in breast cancer by paired-end RNA-sequencing. Genome biology. 12, 6 (2011).
- Ilott, N. E., Ponting, C. P. Predicting long non-coding RNAs using RNA sequencing. Methods. 63, 50-59 (2013).
- Sun, L., et al. Prediction of novel long non-coding RNAs based on RNA-Seq data of mouse Klf1 knockout study. BMC bioinformatics. 13, 331 (2012).
- Luo, S. MicroRNA expression analysis using the Illumina microRNA-Seq Platform. Methods in molecular biology. 822, 183-188 (2012).
- Bolduc, F., Hoareau, C., St-Pierre, P., Perreault, J. P. In-depth sequencing of the siRNAs associated with peach latent mosaic viroid infection. BMC molecular biology. 11, 16 (2010).
- Chepelev, I., Wei, G., Tang, Q., Zhao, K. Detection of single nucleotide variations in expressed exons of the human genome using RNA-Seq. Nucleic acids research. 37, 106 (2009).
- Djari, A., et al. Gene-based single nucleotide polymorphism discovery in bovine muscle using next-generation transcriptomic sequencing. BMC genomics. 14, 307 (2013).
- Murphy, D. Gene expression studies using microarrays: principles, problems, and prospects. Advances in physiology education. 26, 256-270 (2002).
- Chen, K., et al. RNA-seq characterization of spinal cord injury transcriptome in acute/subacute phases: a resource for understanding the pathology at the systems level. PLoS one. 8, 72567 (2013).
- Marioni, J. C., Mason, C. E., Mane, S. M., Stephens, M., Gilad, Y. RNA-seq: an assessment of technical reproducibility and comparison with gene expression arrays. Genome research. 18, 1509-1517 (2008).
- Ramskold, D., Kavak, E., Sandberg, R. How to analyze gene expression using RNA-sequencing data. Methods in molecular biology. 802, 259-274 (2012).
- Glenn, T. C. Field guide to next-generation DNA sequencers. Mol Ecol Resour. 11, 759-769 (2011).
- Trapnell, C., et al. Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks. Nature protocols. 7, 562-578 (2012).
- Trapnell, C., Pachter, L., Salzberg, S. L. TopHat: discovering splice junctions with RNA-Seq. Bioinformatics. 25, 1105-1111 (2009).
- Langmead, B., Trapnell, C., Pop, M., Salzberg, S. L. Ultrafast and memory-efficient alignment of short DNA sequences to the human genome. Genome biology. 10, 25 (2009).
- Trapnell, C., et al. Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nature. 28, 511-515 (2010).
- Anders, S., Huber, W. Differential expression analysis for sequence count data. Genome biology. 11, 106 (2010).
- Quinlan, A. R., Hall, I. M. BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics. 26, 841-842 (2010).
- Cheranova, D., et al. RNA-seq analysis of transcriptomes in thrombin-treated and control human pulmonary microvascular endothelial cells. J Vis Exp. , (2013).
- Zhang, H. M., et al. AnimalTFDB: a comprehensive animal transcription factor database. Nucleic acids research. 40, 144-149 (2012).
- Wu, J. Q., et al. Systematic analysis of transcribed loci in ENCODE regions using RACE sequencing reveals extensive transcription in the human genome. Genome Biol. 9, 3 (2008).
- Wu, J. Q., et al. Large-scale RT-PCR recovery of full-length cDNA clones. Biotechniques. 36, 690-696 (2004).
- Wu, J. Q., Shteynberg, D., Arumugam, M., Gibbs, R. A., Brent, M. R. Identification of rat genes by TWINSCAN gene prediction, RT-PCR, and direct sequencing. Genome Res. 14, 665-671 (2004).
- Dewey, C., et al. Accurate identification of novel human genes through simultaneous gene prediction in human, mouse, and rat. Genome Res. 14, 661-664 (2004).
- Wu, J. Characterize Mammalian Transcriptome Complexity. , LAP Lambert Academic Publishing. (2011).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}